Das Thema der Grafischen Programmierung ist als Alternative oder besser Ergänzung zur Programmierung in den allgemeinen statischen
textuellen Sprachen C, C++, Java und C# dargestellt. Nach Meinung des Verfassers hat die textuelle Programmierung dann Nachteile,
wenn es um die umfängliche Gesamtheit der Software geht. Für Details ist eine textuelle Programmierung in statischen Programmiersprache,
also insbsondere C für Hardwarenähe und Betriebssystem, (zeitlos) passend. Übertragen gilt das auch für Algorithmen, die in
Java oder C# sehr gut darstellbar sind.
In Abgrenzung zum hier dargestellten Thema: Die Programmierung in einer bestimmten Anwendungsumgebung, Geräte/Anlagen-Programmierung
und dergleichen, wird oft grafisch ausgeführt. Dies sind jedoch aus Sicht dieses Artikels Speziallösungen, für die diese Überlegungen
teils zutreffen aber bereits passend gelöst sind.
Als Tool der Grafischen Programmierung wurde Simulink (https://de.mathworks.com/products/simulink.html) ausgewählt, nach guten Praxiserfahrungen. Die in diesem Abschnitt dargestellten Aussagen sind aber auch auf ähnliche Programmiersysteme
der Function-Block-Grafik übertragbar. Eine Abgrenzung zu UML-Grafiken ist im Artikel dargestellt.
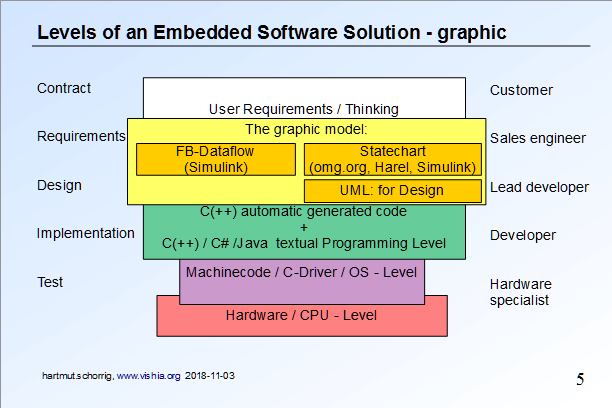
1.1 Software soll durchschaubar sein für Kunde, Vertrieb, Management
Auf die Frage meines Vertriebs-Kollegen, was denn im neuen Update so alles geändert wurde, versuche ich zu erklären: Dies,
das und jenes. Mein Gegenüber macht große Augen, weil, er versteht nicht wo von ich rede.
Software kommt dem Nicht-Softwerker oft undurchsichtig, obscure, vor. Was ist da drin in der Kiste? "Bitte schreibe konkrete
Features auf, die ich dem Kunden weitergeben kann" .... Was habt ihr schon wieder geändert?
Bei einer Anordnung von mechanischen Teilen oder einer Hardware ist das einfacher. Da sieht man was das ist (auch wenn das
Detail vielleicht nicht genau durchschaut wird). Geht das bei Software auch?
Meine Antwort "Ja" auf diese Frage besteht aus zwei Komponenten:
1) Die Software muss so in Blöcke zergliedert werden, dass dem Anwender begreiflich ist: Dieser Block ist für dies, und der
andere Block für jenes zuständig. Damit wird das Ganze begreifbar (man kann den Block, wenn auch nur virtuell, greifen).
2) Wichtig ist die Sicht auf die Daten, nicht die Algorithmen und schon gar nicht die C-Zeilen. Der Programmablauf ist kaum
vermittelbar, zuviel, andere Denkweise. Wenn aber jedem Block bestimmte Daten zugeordnete werden, kann der Anwender etwas
damit Anfangen: "Dort stehen die Parameter, die Du ja kennst. Dort kommen die Messwerte hinein, werden skaliert" ...usw.
Mit dem zweiten Punkt ist man eigentlich bei der Objektorientierung, die den Blick auf die Daten als primär gegenüber dem
Blick auf Abläufe (Programmstrukturen) betont. Eigentlich recht klar für den Informatiker. Interessant wird es aber, die Daten
aus einer laufenden Software auf dem PC oder auf einem Gerät sofort darzustellen, visuell, bei laufender Software. Siehe dazu
Chapter: 1.8 Inspector-DataViewing Zugriffsrechte.
Der erste Punkt deutet klar auf eine grafische Progarmmierung. Diese ist ein Muss, wenn Software durchschaubar sein soll.
Im Folgeabschnitt ist dazu ein Beispiel gegeben. Dabei wird Simulink als Vertreter der Funktionsblock-Darstellungen klar der
Vorzug gegeben gegenüber UML.
1.2 Alternativen UML oder Functionblockdarstellung (z.B. mit Simulink)
UML (Unified Modelling Language) ist eine bekannte Herangehensweise der grafischen Programmierung mit etwa 14 Diagrammarten von Use cases über Object-Model-Diagramme
(Klassen / Package oder Modulbeziehungen) bis hin zu Zustandsmaschinen in der Ausprägung Statechart. UML-Tools sind verbreitet, gut und wichtig auch für die Softwareentwicklung selbst, aber eventuell nicht hinreichend.
Schon lange vor der UML (1977 erste IEC61131-Norm) ist die Funktionsblockdarstellung entstanden. Mit dieser Norm ist sie als
"FBD" (Function Block Diagram) oder "FUP" beispielsweise in S7-Steuerungen (Siemens) bekannt. Das gleiche Grundprinzip, wenn auch in umfangreicherer Ausprägung,
findet man in Simulink-Diagrammen oder ähnlichen Tools der Simulationssteuerung. Grundprinzip ist die Darstellung einer Funktionalität
als Block und deren Verbindungen, die in der Regel als Datenfluss aufgefasst werden. Diese Diagrammart, im folgenden als FBCD = FunctionBlockConnectionDiagram bezeichnet) ist in der UML am ehesten mit dem Object Diagram präsent. Der Unterschied zu FBCD-Darstellungen (sowohl für das S7- als auch Simulink-Beispiel, verallgemeinert) ist allerdings,
dass ein ObjectDiagram mit einem Rechteck-Kasten die gesamte Instanz einer Klasse darstellt, mit mehreren Operationen. Der
FunktionsBlock ist dagegen eine Operation. Den Begriff der "Klasse" gibt es hierbei nicht.
Wir finden für die Grafische Darstellung von Programmen also im Wesentliche 2 Welten vor, eine mit der 'Unified' UML-Herangehensweise,
vertreten von mehreren Toolherstellern, die andere aus der FunctionBlock/Datenfluss-Darstellung in den unterschiedlichsten
Tool/Hersteller-spezifischen Ausprägungen. Die UML-Welt ist stark auf Softwarestrukturierungs-Unterstützung insbesondere für
große sonst unübersichtliche Softwareprojekte ausgerichet. Die FBCD-Darstellungen haben als Zielgruppe die einfache grafische
Zusammenschaltung von Funktionen, unterstellt zumeist für eher kleinere Anwendungen. Dieser unterschiedliche Fokus mag der
Grund dafür sein, warum die FBCD-Diagrammart nicht in die UML-Welt aufgenommen wurde.
Wie soll sich der Anwender mit dem Wunsch nach grafischer Programmierung orientieren? Die einzelnen Tools/Hersteller der FBCD-Welt
bieten jeweils abgerundete, d.h. in sich abgeschlossene Lösungen an, so die S7-Steuerungen mit dem TIA-Portal (https://de.wikipedia.org/wiki/Totally_Integrated_Automation) oder Simulink mit seinen diversen Packages für spezifische Hardwareanbindungen (https://de.mathworks.com/hardware-support/raspberry-pi-matlab.html). Diese Welten sind zumeist nicht kompatibel. Wenn die Nachbararbteilung oder der neue Kooperationspartner nicht auf das
beispielsweise bisher favorisierte Simulink setzt, dann ist die Zusammenarbeit schon etwas erschwert.
An dieser Stelle ist aus Anwender (Embedded-Developer)-Sicht eine hohe Offenheit notwendig. Aus meiner Sicht ist das Bindeglied
die gemeinsame Implementierungsplattform, die meist C teils in C++-Ausprägung oder eine adäquate statische Quelltext-Programmiersprache
im Fokus hat. Die UML ist unifiziert, sowohl bezügliche eines gemeinsamen Diagramm-Verständnisses als auch über den XMI-Datenaustausch
(https://de.wikipedia.org/wiki/XML_Metadata_Interchange) oder ein mögliches Aktualisieren des UML-Datenhaushaltes (Repository) aus den (generierten und/oder handveränderten) Quelltexten
(oft als Roundtrip bezeichnet). Was Simulink betrifft: Neben der Orientierung des Herstellers auf diverse supportete und extra zu beziehende 'Hardware-Support-Packages' ist eine Offenheit zu beobachten, die sich sowohl
an der Codegenerierung für C zeigt. So wird das Mapping zwischen generiertem Code und Modell unterstützt. ...als auch die
Möglichkeit des direkten Einbindens von Kernfunktionalitäten in C(++) über S-Functions ist möglich. Letzteres ermöglicht den
Hardware/System/C-orientierten Ersteller eigener Embedded Lösungen, wie gewohnt in C Hardware- und Betriebssystemzugriffe
zu programmieren, aber die Zusammenfassung dieser Einzelfunktionen zu einer gesamten Applikation über die grafische Modellebene
mit Codegenerierung zu realisieren. Das ist ein geeigneter Ansatz der Grafischen Progarmmierung.
Was fehlt: Hat man ein Grafisches Modell speziell in Simulink (mit Kernen in C) und möchte dies in einer anderen Abteilung
(beispielsweise beim Kooperationspartner der nicht auf Simulink setzt) weiter bearbeiten, dann ist der gezielte verlustfreie
Datenaustausch, wie er in der UML-Welt mit dem XMI geboten wird, vorderhand nicht möglich. Das Einbinden fertig übersetzter
Modelle in andere Tools wird zwar unterstützt (meist über dll), nicht aber die Konvertierung der Modellquellen. Es ist dafür
noch etwas Zukunfsarbeit notwendig, Möglichkeiten gibt es.
Aufgrund praktischer Erfahrungen mit Simulink zeige Ich in folgenden Ausführungen die Grafische Programmierung mit Simulink
und C. Die Verallgemeinerung - Nutzung eines Austauschformates, Übertragung der Prinzipien auf adäquate Plattformen, sei der
Zukunft zugeordnet.
Das Video zeigt, wie mit Simulink-Mitteln sehr plastisch Module und ihr Zusammenspiel auf Kundennähe gebracht werden können.
Interessant ist, dass die Statechart-Technik in den 80-gern von David Harel entwickelt und über das Tool Statemate (i-Logix)
in die UML-Welt hineingebracht, auch in Simulink präsent ist. An dieser Stelle treffen sich die Toolwelten. Zustandsmaschinen
im allgemeinen und die Statecharts mit der guten Darstellung von geschachtelten Zuständen und Parallelitäten mit der Eventverarbeitung
sind durchaus ein Bindeglied des Verständnisses der Software bis hin zum Kunden.
Ein weiterer wichtiger Punkt ist die Orientierung auf Objekte wie sie in der Softwarewelt, bisher aber noch nicht in der FBCD-Welt
('FunctionBlockConnection') gängig ist.
Der dritte Punkt ist die Beobachtbarkeit von Daten mit dem Inspector-Konzept, hier ebenfalls präsentiert.
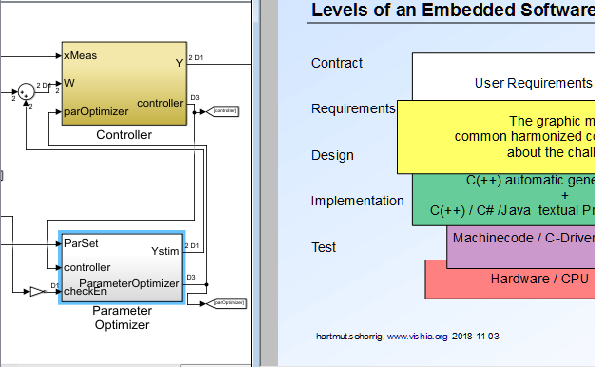
Wenn Sie ihrem technisch orientierten Vertriebler ein solches Bild präsentieren, dann können Sie die Funktion des Gerätes
erklären. Die Sollwerte (RefValue) werden hier über eine Ethernet-Schnittstelle empfangen, das erledigt das gezeigte Modul.
Wesentlich hierbei soll sein: Es handelt sich um eine Regelung mit Parameteroptimierung aufgrund Streckenparameter und Test-Stimulation.
Es wird also auf den eigentlichen Ausgang etwas aufaddiert, das ist im Bild deutlich sichtbar. Die Parameteroptimierung benötigt
die gemessenen Werte. Details lassen sich verbal erklären. Die Frage "Was habt ihr denn schon wieder geändert" ist dann lokalisierbar
beantwortbar, beispielsweise "Bugfix bei der Messwertaufbereitung" mit Verweis auf genau dieses Modul.
Zum Umfang eines solchen Modells: In dieser Auflösug sind die Module noch erkennbar. Auf einem Full-HD-Monitor passt etwa
6..8 mal mehr, also ca. 20 Module. Das ist noch überschaubar - wichtig ist die Übersicht und auch Freiflächen. Mit einer Schachtelungstiefe
(Submodule) von 4..5 kommt man dann auf eine doch beträchtliche Komplexität, die aber immer noch überschaubar sein sollte.
Das ist das Ziel des guten Designs der Grafik.
Das Bild zeigt das Main-Diagramm des Beispiels. Typisch ist die Unterteilung in das zu realisierende Softwaremodul Device, die Umgebungssimulation Environment und diverse Mess-Ankopplungen auf dieser Ebene.
Man kann den Kunden direkt einbeziehen, denn er wird seine Umgebung am besten kennen und entweder selbständig zuarbeiten oder
mit Ihnen im Detail diskutieren. Es gibt dabei zwei oder drei Arten von Kunden:
Ohne Erfahrung in Simulation, aber mit Interesse: Dann können Sie das sehr verbreitete und leistungsfähige Tool Mathworks Simulink dem Kunden empfehlen.
Mit weitreichender eigener langjähriger Erfahrung mit anderen Simulationswerkzeugen: Dazu gibt es Bridges, typischerweise
können andere Simulationstools eine Windows-DLL exportieren, die in Simulink einbezogen werden kann.
Diese zweite Variante ist arbeitsaufwändig und speziell, trifft aber auf vorhandes Knowhow.
Der dritte Kundentyp ist der ohne Erfahrung und Intension. Zeigen Sie ihm diese Technik mit Simulink.
1.5 Modularisierung und Objektorientierung
Topic:.GraphProgr.ObjOmodule.
Last changed: 2019-02-24
Das Video zeigt die Herangehensweise für den Entwurf der Modulverbindungen entsprechend der Beschreibung in den folgenden
Unterabschnitten-
Die Modularisierung der Software ist ein Schlüssel für durchschaubare pflegbare Software - divide et impera gilt wie bei der
Römischen Länderverwaltung auch hier. Ein Modul lässt sich funktional vollständig durchschauen, einzeln testen. Der Zwang
zur Modularisierung und Schnittstellendefinition führt letzlich zur guten Softwarearchitektur. Mit Blick auf die Gesamtfunktionaltität
können die einzelnen Module als Black Box betrachtet werden, die Gesamtheit wird beherrscht.
Simulink unterstützt die modulare Softwarestruktur mit einzelnen FunctionBlocks, die intern wieder eine Substruktur als Teilmodell
haben können, referenzierte Subsysteme und Teilmodelle als Modul in Libraries.
Die Modularisierung der Software wird oft mit der Objektorientierung in den Zusammenhang gebracht: Module haben ihre innere
Funktionalität mit ihren Daten. Objektorientierung ist die Bindung der Funktionalität an die Daten. 'Zeige mir Deine Daten
und ich sage Dir wer du bist' - Aus diesem Leitspruch werden die Daten zu einer Klasse in einem ObjectModelDiagram der UML
im mittleren extra Abschnitt gezeigt. Dies ist nicht im Widerspruch zur private-Kapselung der Daten, die compiletechnischer
Natur ist und nichts mit 'verbergen' oder 'geheimhalten' der Daten zu tun hat.
Die Objektorientierung lebt von der Referenzierung. Mit einer Referenz auf eine aggregierte oder assoziierte Instanz einer
Klasse greift man auf die Instanz zu. Die Referenzierung ist in allen Programmiersprachen kein Thema. Geklärt, funktioniert.
Das rechtsstehende Bild zeigt die Verbindung zweier Module in einem Simulink-Modell mit sogenannten Handle, das sind die Referenzen.
Die Handle-Nummern werden intern in Speicheradressen umgesetzt.
Die Referenzierung steht nun (scheinbar) im Widerspruch zur Datenflussorientierung in Simulink-Modellen. Man kann dies nicht
als Widerspruch auffassen sondern auf höherer Ebene verwirklicht sehen: Per Datenfluss wird der Zugang zu den Daten weitergegeben.
Die Aggregation in UML-ObjectModelDiagram von der nutzenden zur genutzten Klasse gerichtet wird hier gedreht: Das benutzte
Objekt/Modul gibt seine Referenz an das nutzende weiter. Mit diesem Zugangsschlüssel kann dann das nutzende Modul ohne viele
Datenverbindungen auf das genutzte in mehreren Funktionalitäten mit ihren Daten zugreifen.
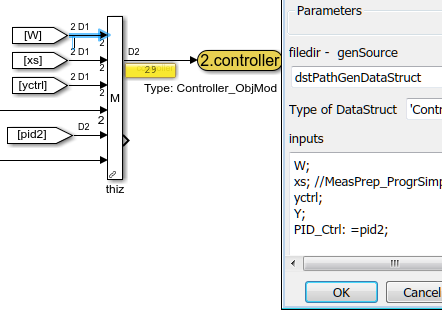
Es verbleibt die Frage: Wie kommt man zu den Referenzen in Simulink. Das rechsstehende Bild zeigt einen SFBlock 'DataStructMng_Inspc',
der mit entsprechender Parametrierung im Simulink die Daten des Moduls definiert und als Referenz ausgibt.
Es gibt es zwei Lösungsansätze, die beide mit Kern in C arbeiten:
In der Simulink lib_Inspc befinden sich SFblocks, die per Parametrierung Daten halten und zugreifbar gestalten. Diese sind
die erste Wahl um im reinen Simulink ohne C-Ebene die Daten objektorientiert zu organisieren.
Spezielle Kern-Routinen in C für die Datenhaltung in Sfunctions verkleidet, im Zielsystem direkt aufgerufen. In C kann in
diesen Kernroutinen auch Datenkonsistenzlösungen über Betriebssystemdienste (Mutex, AtomicAccess, Wechselpuffer) gelöst werden.
Dazu muss man mit der Modellierung aber C betreiben. Die Datentstrukturen werden mit struct in Headerfiles angelegt, die als Teil des Simulink-Modells aufgefasst werden. Ein Übersetzer, der von Annotationen in den
Headerfiles gesteuert wird, generiert den notwendigen Sfunction-Wrapper und die tlc-Files für die Zielsystemcodegenerierung.
Siehe Chapter: 1.14 Generierung der S-Funktionen aus Informationen in Headerfiles
Beide Ansätze arbeiten zusammen. Wesentlich für die eigentliche Modellierung ist aber der erste Ansatz. Die Frage, wieviel
C darf in Simulink drin sein, ist im Chapter: 1.9 Simulink und / oder C ? etwas beleuchtet.
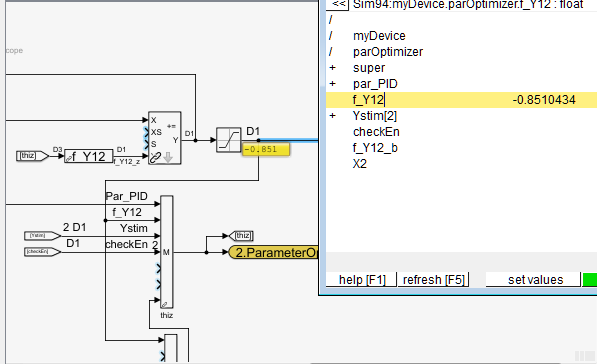
Der Zugriff auf Daten mit diesem SFBlocks ist auf dem Bild rechts sichtbar. Hier wird aus einem anderen Model 'parOptimizer'
eine Referenz per handle geholt, es werden dann auf die Daten aus dem anderen Modul zugegriffen, über set-Funktionalität für
'tune_fY12', über eine get-Funktion in der schnellen Abtastzeit für 'fY12' und ein Handle-Abgriff für die Parameter des Reglers,
die in dem anderen Modul aufbereitet werden. Dieser Ausgang ist ein Handle in der Initialisierungsphase.
1.6 Inspector-DataViewing für Simulink und im Target
Der Inspector wurde als Konzept schon vor über 10 Jahren (ca. 2005/06) unabhängig von Simulink für den Datenzugriff auf Embedded
Targets entwickelt. Herausstellungs-Merkmal ist, dass dynamisch angelegte Datenstrukturen angeschaut werden können. Adäquate
Systeme sind eigentlich immer gängig und präsent, arbeiten aber häufig mit den statischen Daten, deren Speicheradressen über
Mapfiles und Listings ermittelt werden. Die Inspector-Lösung arbeitet im Target mit Reflection-Informationen die Namen und
Offsets von Elementen in Strukturen enthalten. Neben diesen Informationen ist dann nur die Root-Daten-Startadresse notwendig.
Es können jedenfalls auf dynamisch zur Startup-Zeit angelegte Daten zugegriffen werden, auch auf laufzeitdymamische Daten.
Ein Vorteil ist: Alle relevanten Informationen sind im Code des Zielsystems gespeichert. Man braucht nicht den richtigen Configfile
um nicht auf für die gegebene Version ungültige Adressen zuzugreifen.
Ein kleines Zielsystem, dass den Aufwand der etwas umfangreichen Reflection-Informationen nicht haben kann, wird über einen
InspcTargetProxy angesteuert. In diesem Fall stehen die Reflection-Informationen nicht im Target, wohl aber im zweckmäßgi
zur Anlagen zugehörigen Proxy. Das kann ein Anlagen-PC sein, ein kleiner Raspberry-Pi, oder auch das korrekt geladene File
im Inbetriebsetzer-Notebook.
Die Kommunikation mit dem Zielsystem erfolgt per Ethernet oder seriell. Die Kommunikation zwischen Target und Proxy kann auch
über Dual-Port-RAM oder dergleichen erfolgen, wenn der Proxy-Prozessor auf dem gleichen Board wie der Target-Prozessor sitzt.
Mit der rechts im Bild stehenden SFunction "Service_Inspc" ist der Inspector auch für Simulink zugänglich.
Im Video wird gezeigt, wie die gleichen Informationen im Modell im Simulink und auf dem Target zugänglich sind. Der Unterschied
zwischen Daten-Viewing mit Simulink-Bordmitteln und Inspector wird verdeutlicht.
Objektorientierung bedeutet im Kern die Bündelung der Daten an ihre Operationen. Eigenschaften wie Vererbung, Ableitung, virtuelle
Funktionen, bekannt aus C++, Java &co sind add-ons, die sich aus der Logik ergeben und wünschenswert sind. Es gibt aber diesbezüglich
Stimmen, die vor der ausufernde Nutzung von Vererbung warnen und gar mit der "Funktionalen Programmierung" eine neue Zeitära
einleiten wollen. Das ist teils berechtigt. Bleiben wir also beim Kern - Bindung der Daten (Objekte) an ihre Operationen in
einem Modul.
Damit ist der Zugriff auf die Daten des Moduls, um interne Funktionen zu debuggen, nicht im Schrittbetrieb, sondern anhand
des Verlaufs der Daten, verbunden. Dazu sind die im Video gezeigten Datenbündler, der statt Bussen oder Mux im Simulink eingesetzt
werden, geeignet. Der Zugriff erfolgt von außen über den Inspector und kann genauso im Zielgerät erfolgen, wenn der Inspector-Zugriffsdienst und die notwendigen Reflection dort ebenfalls implementiert werden.
Für die Fehlersuche in der Entwicklung ist es wünschenswert, auf alle Daten zugreifen zu können und auch alle Daten modifizieren
zu können, wenn sie nicht vom Rechenprozess selbst belegt werden. Man kann dies so ausbauen, dass spezielle Testfunktionen
mit vorgesehenen Variablen freigeschaltet werden oder Parameter bis an Grenzen verstellt werden können. Das ist aber mit dem
Background des Entwicklungstests oder einer diffizilen Fehlersuche am Zielgerät unter Kundenbedingungen, aber vom Spezialisten,
gedacht. Der Datenzugriff über den Inspector ist andererseits tauglich auch für eine Kundenwartung oder als universelles Parametrierungstool.
Folglich muss mit Zugriffschutz (Passwort) gearbeitet werden. Eine Endauslieferung ohne bestimmte Zugriffsmöglichkeiten bedeutet
neben dem Zusatzaufwand, dass im Ernstfall der unvorhergesehenen Servicemaßnahme die Zugriffsmöglichkeiten nicht verfügbar
sind.
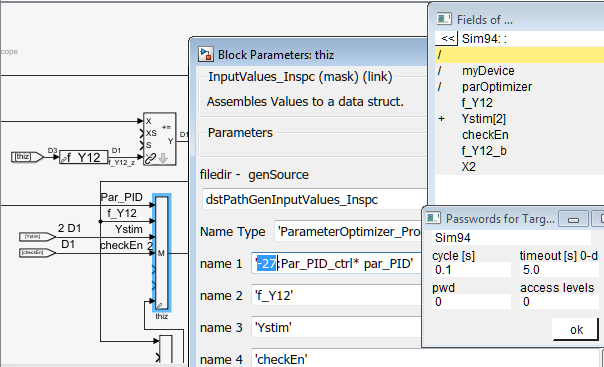
Das Video und Bild zeigt, wie der Passwortschutz im Modell ausgedrückt werden kann: Der Eingang bekommt einfach ein Passwort-Level
von 0 bis 7. Der Kunde kann dies nicht ändern, auch wenn er über das Simulink-Modell selbst verfügt, dazu müsste er noch die
Zielsoftware erstellen und selbst implementieren. Nicht das Passwort selbst sondern das Level wird im Modell eingegeben. Die
Passwortverwaltung mit Schlüssel in jedem Inspector-Telegramm ist nach den üblichen Algorithmen eingebaut und im Zielsystem
in der Hand der Entwicklung.
Die grafische Programmierung - mit Simulink - wird deshalb hier favorisiert, weil es nur so gelingt, Komplexitäten zu beherrschen
und eine Einheit von Dokumentation, Kunden-Gesprächen und tatsächlicher Software herzustellen. Die Implementierung ist und
bleibt aber dennoch C. Vereint wird dies durch zwei Ansätze:
Generierung des C-Codes aus dem Modell
Einbeziehung von C-Code in dem Modell
An Stellen, an denen keine Komplexität vorherrscht und auch nicht engmaschig Algorithmen mit dem Kunden abgestimmt werden,
können Sie weiterhin direkt in C arbeiten. Die Verständlichkeit der Software leidet damit nicht, denn C ist einfach lesbar,
oft sind es mathematische Gleichungen. Insbesondere auf Treiber-, Betriebssystem- und Hardwareebene ist C direkt besser. Nur
wenn diese Schicht Ihnen jemand abnimmt, er für Sie die Hardwareanpassung realisiert, können Sie C vergessen. Das wäre allerdings
dann der Fall, wenn etwa der Kunde Anpassungen im Gerät selbst vornimmt ('Projektierung des Gerätes'), direkt im Modell oder
in einem übergeordneten Teilmodell.
Der intene Aufbau der Software auf den äußeren Schalen ist mit der grafischen Programmierung geöffnet. Die Softwarestruktur
muss mit der Grafik übereinstimmen, Codegenerierung aus dem Modell ist selbstverständlich.
Damit entsteht eine starke Verbindung der Software mit der Dokumentation. In der zeilenorientierten Programmierung gibt es
diese Verbindung nicht wirklich. Die Struktur der Software muss von daher schon gut durchdacht sein. Softwarestrukturierungen
entstehen nur in der Theorie Top-Down aus einem durchdachten Design hin zur Implementierung. In der Praxis - auch ohne das
Paradigma der Agilität, wird in Details nachgebessert bis es in der modularen Struktur der Software kracht und knirscht. Der
Entwickler ist nun schon wegen des eignenen Durchblicks zum Refactoring geneigt. Für das Management erscheint das oft nur als 'Kostenfaktor'.
Die grafische Programmierung hilft hier ungemein, da die Modulstruktur sichtbar ist und dessen Zweckmäßigkeit offen liegt.
Die Details der Programmierung, Treiberebene, Hardwareschnittstellen etc. sind die Teile in denen sich oft Know-how verbirgt
und die nicht offengelegt werden sollen. An diesen Stellen ist man aber oft schon 'unten' in der Modularität, klar strukturiert,
keine komplexen Abhängigkeiten. Hier gibt es zumeist nicht wirklich Probleme. Diese Teile sind also auch leicht aus der grafischen
Darstellung herauslösbar. Probleme existieren im Mittelteil der Module. Diese geschickt zu schneiden wird mit der Grafik überschaubar.
1.11 Design freeze und Abstraktion
Topic:.GraphProgr.freeze.
Wozu gibt es ein Design freeze. Antwort: Um die Entwickler zu ärgern. Nein, das Design freeze ist notwendig damit die betreffende
Komponente unverändert bleibt wenn man sich auf eine andere Komponente konzentrieren will. Wenn in jeder Komponente von entsprechenden
Entwicklerteams ständig Änderungen passieren, dann bremst der Detailteufel den Entwicklungsprozess aus. Die andere Notwendigkeit
des Design freeze, vor der Auslieferung und vor dem Test, sei hier erwähnt aber nicht das folgende Thema.
Wann gilt eine Komponente als getestet und für anderen Personen als gebrauchsfähig? Wenn die Quellen getestet sind und eine
entsprechende Erklärung des Entwicklerteams vorliegt? Nein, das reicht nicht. Eine Komponente kann nur in der ablauffähigen
Form als getestet erklärt werden. Das bedeutet, compiliert. Entweder als fertiges Gerät oder als ladbaren Binärcode im Kontext.
Für die grafische Programmierung bedeutet das: Die Komponente aus einem anderen Entwicklerteam muss binär eingebunden werden
können. Wenn man das gesamte Modell der fremden Komponente dazuladen muss, dann kann es einerseits wegen unkommunizierten
Detaileinstellungen Irritationen geben, andererseits dauert der Modellstart unnötig lange bei großen Komponenten.
Das Bild zeigt die Verbindung dreier Komponenten (Module in der Grafik) mit einem Handle, die eine Datenreferenz darstellt.
Die Komponente rechts unten hat ein Designfreeze. Die Daten werden von der linken Komponente bereitgestellt. Folglich muss
auch die Datenstrukturierung der linken Komponente gefreezed sein, darf sich nicht ändern. Man möchte aber diese Komponente
mit der Komponente rechts oben bearbeiten, auch die Daten in der Referenz-Schnittstelle noch anpassen. Das geht mit Abstraktion
und Vererbung:
Die Kompontente rechts unten benutzt eine Abstraktion der Schnittstelle, nur diese ist gefreezed. In C++, C#, Java und anderen
objektorientierten Sprachen gibt es dazu das Sprachmittel der Vererbung: class MyClass extends BaseClass in Java. Die Komponente rechts unten nutzt eine Basisklasse der Schnittstelle deren Quelle unverändert ist, damit ist diese
Kompontente compiliert. Für die Schnittstelle der noch zu bearbeitenden Komponenten wird die abgeleitete Klasse benutzt, in
der die notwendigen Änderungen stattfinden dürfen. Die Entscheidung, nicht zwei verschiedene Schnittstellen zu benutzen, ist
eine Architekturentscheidung, die nicht wegen temporärer Entwicklungsarbeiten umgestoßen werden soll. Die Verwendung einer
Abstraktion der Schnittstelle ist auch dann zweckmäßig, wenn im Beispiel Component_C allgemeingültig ist und mit der Abstraktion befriedigt ist, die anderen Komponenten aber etwa geräte- oder projektspezifische
Erweiterungen enthalten, wegen denen nicht jedesmal Component_C erneut compiliert werden soll. Die Abstraktion und als Conterpart die Vererbung ist dafür ein probates Sprachmittel.
Kann dies auch grafisch gehen? Die SFblocks DataStructMng_Insps verfügen über das Feature der Bildung von Basis-Strukturen mit eigenem Headerfile. Damit ist diese Herangehensweise möglich.
Im Video werden Details gezeigt.
1.12 Automatische Codegenerierung und Einbindung handprogrammierter C(++) codes
Topic:.GraphProgr..
Nutzt man die grafische Programmierung einschließlich Simulation dann ist es ein Zusatzaufwand, wenn die gefundenen Module
und Relationen danach manuell in C programmiert werden müssen. Mehr noch, bei Diskussionen an der Grafik, deren Änderung mit
Simulationstest muss danach die entsprechende Stelle im C-Code gefunden werden, um auch in der Zielsoftware nachzubessern.
Dort hat aber der Programmier vielleicht schon einen Detailfehler korrigiert, der so nicht im Modell sichtbar war. Das Modul
und der C-Code sind schon auseinandergelaufen. Diese Divergenz wird sich fortsetzen und zum Projektabschluss wird dann aus
Zeitgründen nur noch im Code gefixt. So das Negativscenario.
Konsequent ist daher mit der Grafischen Programmierung immer auch die automatische Codegenerierung aus der Grafik verbunden.
Dies wird von Simulink seit Jahren (Jahrzehnten) mit guter Erfahrung unterstützt, auch von anderen grafischen Entwicklungsumgebungen.
Aus dieser Jahrzehnte-Erfahrung heraus müsste man meinen, niemand programmiert noch per Hand (außer Systemprogrammierer und
Nerds). Das ist aber nicht so. Woran liegt das?
Die Entwicklungsumgebungen für die Zeilenprogrammierung in C/C++ und höhrere Programmiersprachen sind auch besser geworden.
Autocompletion, Syntaxhighlighting, Syntaxfehlersuche während des Schreibens, Gute Datenanzeige in Verbindung mit dem Editor,
Debugging am Quelltext.
C ist maschinennahe, man weiß was man hat.
Ist der generierte Code für Grenzfälle rechenzeiteffektiv?
Debugged wird oft am C-Quellcode und an den realen Daten im Speicher.
Damit gibt sich eine Diskrepanz. Eine große Personengruppe akzeptiert nur die eigenen manuell programmierten Zeilen. Eine
andere Personengruppe möchte aus Grafik generieren, betreibt dies erfolgreich schon seit Jahren und versteht nicht die fehlende
Akzeptanz.
Das Bild rechts zeigt Praxis und Anspruch der zweiten Gruppe: Es geht per Knopfdruck aus dem Grafiktool direkt ins Zielsystem.
Dieser Anspruch funktioniert, wenn es sich um eine vorbereitete bekannte Umgebung handelt. Es hat sich jemand um die Details
gekümmert.
Dieses Bild ist eine Erweiterung des Knopfdruckanspruches und öffnet die Dinge die dahinterstehen:
Für den Endanwender, Projektierer, nur grafisch arbeitenden Funktionsdesigner gibt es auch hier den Knopfdruchanspruch. Der
graue Bereich, die Aura des C/++-Developer, ist nicht notwendig wenn alles läuft. Die eigentlich zwei Schritte, Codegenerierung
aus dem Modell und Compilierung für das Zielsystem, lassen sich zu einem Knopfdruck vereinen, besser noch zu einem Script
das nachvollziehbar die Generierung aus gespeicherten Files in einer Softwarerevisionsverwaltung, ausführt.
Ist das Zielsystem ein eigenes, nicht ein Standardsystem, dann muss irgendjemand die Anpassung vornehmen und auf Änderung
reagieren. Das ist der C/++-Entwickler. Er kennt die Compilertools und hat sich mit den Einstellungen der Codegenerierung
vertraut gemacht. Er erkennt, wenn etwas im Modell ungünstig für die Implementierung designed ist. Er kann auf Lo-Level-C-Code
oder maschinennahe auch mit dem generierten Code testen.
Genau genommen arbeitet der C/++-Entwickler wie bisher. Nur das ihm die Arbeit des Nachcodierens des Modells abgenommen wird,
dafür muss er sich aber mit der Erscheinungsform des generierten Codes 'herumschlagen', muss diese kennen und aktzeptieren.
Spätestens nach der zweiten Änderung im Modell wird er aber nicht mehr kritisch jede Zeile beäugen sondern wird grob darüberschauen
ob eine ungünstige Rechenzeitkonstellation hinzugekommen ist oder dergleichen und dort keine Detailarbeit hineinstecken. Er
wird am Modell mitarbeiten.
Nun ist die Basis bereitet für eine gute Zusammenarbeit:
Der Funktionsdesigner arbeitet am Modell, testet am Modell, hat den Knopfdruckanspruch.
Der Implementierungsentwickler kennt die Arbeit am Modell, kümmert sich mehr um Details der Einstellung von Generieroptionen,
testet Knackpunkte, schreibt hardwarenahe Treiber und bindet diese in das Modell ein.
Der Gesamt-Software-Test wird auf drei Ebenen ausgeführt:
Funktionstest mit Umgebungssimulation im Modell
Funktionstest mit dem Zielsystem, entweder mit einer simulierten Umgebung oder Integrationstest in der Praxis
Funktionstest mit dem Zielcode aber am PC: Am Zielsystem wird man den Zielcode schlecht einzeln testen, man braucht eine zielsystemspezifischen
Debuggingankopplung etc. Der Test mit dem Zielcode schließt den Test handgeschriebener Code-Teile und Hardwareanbindungen
ein. Auf diesen wird man nicht leichtfertig verzichten können. Der Aufwand, den Zielcode in C am PC in einer IDE zu betreiben,
mit einer passenden Umgebungsanbindung, lohnt sich.
Auf dieser dritten Ebene, Zielcode-Test am PC, kann dann auch sehr gut die Codeoptimalität begutachtet werden. Möglicherweise
muss man Optionen der Codegenerierung anders einstellen, möglicherweise muss man bestimmte Styleguides der Modellierung beachten
und entwickeln.
1.13 Objektorientierung und Wiedererkennung in Modell und Zielcode
Topic:.GraphProgr.ObjOCodeGen.
Der Zielcode ist vielfältig wenn das Modell umfangreich ist. Von Simulink ausgehend, die Mathwork-Tools bieten Hilfen um vom
Modell zum Code und umgekehrt zu navigieren (Hyperlinks in zusätzlich generierten Html-Dokufiles, Comments im Code). Es ist
aber nicht trivial und einfach.
Benutzt man im Modell die Datastruct_Inspc-Daten-FBlocks wie sie insgesamt in Chapter: 2 Objektorientierung und Handleverbindungen im Modell - Details dargestellt sind, dann werden Datenstrukturen in eigenen Headerfiles so angelegt, wie sie in diesen FBlocks in den Parametrierungen
festgelegt sind. Diese struct-Definitionen sind in der jeweiligen Form sichtbar
Im Modell in diesen Datastruct_Inspc-SFBs
Im generiertem Zielcode als typedef struct
Im Inspector sowohl in Simulink als auch auf dem Zielsystem als DataViewing
Hier spielt also der Objektorientierte Gedanke eine wichtige Rolle. Zu den Modulen gehören Daten. Über die Daten werden dann
die Verarbeitungsfunktionen sowohl im Modell als auch im Code gefunden.
Der zweite Wiedererkennungswert zwischen Modell und Code sind die SFunctionBlocks, die direkt in C/++ geschriebene Module
einbinden. Zum FBlock im Modell gibt es den Aufruf der entsprechenden C/++-Operations im Zielcode, über inline optimiert.
Die Objektorientierung im Modell hat also neben den Wert der Rechenzeitersparnis (wegen geparter Datenweiterreichungs-Codes)
den hohen Wert der Wiedererkennung.
Die Eigenständigkeit des generierten Zielcodes neben dem Modell hat zwei Bewandnisse:
Speicherung und Vergleich in einem eigenen Quelltext-Versionsarchiv zur Verfifikation, was ist geändert.
Nutzung für eine Langzeitpflege der Software: Wenn eine Gerätesoftware nach Jahren (Jahrzehnten) in überschaubarem Maß nachgebessert
werden muss, dann ist die Verfügbarkeit und Lauffähigkeit der Zielsystemcompiler ein sehr viel geringerer Aufwand als die
Verfügbarkeit und Bedienfähigkeit eines gesamten Modell-Entwicklungstools.
1.14 Generierung der S-Funktionen aus Informationen in Headerfiles
Topic:.Smlk_de.C_ObjO.genSfH.
Mathworks-Simulink bietet für die Erstellung von S-Funktionen, also Aufrufe von C-Anteilen im Simulink, 3 Wege an:
Ein sogenantes Legacy-Code-Tool soll den Anwender unterstützen, insbesondere vorhandenen C-Code in die Simulink-Modellierung einzubinden. Der Anwender wird
dabei entlastet vom Schreiben der nicht ganz einfachen Wrapper der S-Funktionen, der tlc-Files für die Zielsystem-Codeerstellung
und auch der grafischen Repräsentation der S-Funktion.
Grafische Eingabemöglichkeit anstelle des Schreibens eines Matlab-scripts für das Legacy-Code-Tool
Manuelles Erstellen der Wrapper und tlc-Files.
Der letzte Punkt bietet alle Möglichkeiten. Das sind sehr viele, beispielsweise die Nutzung dynamischer (vom Modell bestimmter)
Port-Eigenschaften, mehrere Abtastzeiten in einem Block, beliebige Parameter. Das manuelle Erstellen ist aber aufwändig. Insbesondere
bei vielen kleinen S-Funktionen ist das erheblich.
Daher hat der Verfasser einen Generator erstellt, der S-Funktion-Wrapper und tlc-File aus Zusatzinformationen im Headerfile
erstellt. Das dazu nötige Script kann mehrere Headerfiles verarbeiten und damit eine Vielzahl meist kleiner S-Funktionen erstellen
('Kerne in C') und muss nicht angepasst werden, wenn sich Operationen im Header ändern. Der Generator arbeitet wie folgt:
Parsen des Headerfiles mit Open-Source ZBNF-Parser, Überführung der relevanten Daten aus dem Header in einen Datenhaushalt in Java. Dazu ist ein Semantic-Script-File
notwendig.
Generieren der Wrapper und tlc-Files aus dem Daten in Java mit einem Open-Source-JZtxtcmd-Generator. Dazu ist ein textuelles Generierungs-Script-File notwendig. Dies enthält alle Befehle und Texte. Der Generator
für Simulink Sfunction-wrapper und tlc ist also ausschließlich mit diesen Scripts realisiert.
Die Tools zum Generieren sind Open-Source, nicht aber die genannten Script-Files. Diese enthalten wesentliches Knowhow der
S-Funktion-Technik des Mathworks-Simulink und schon von daher notwendigerweise geschützt. Mit vorhandener Simulink-Lizenz
und entsprechender Anfangsbetreuung können diese Scripts dann vom Kunden genutzt und auch angepasst werden.
mailto: simulink@vishia.org
Folgendes pdf-Handbuch erläutert die Anwendung dieser Technik:
www.vishia.org/smlk/SmlkOOguide-de.pdf Handbuch für die Einbindung von C über Sfunction in Simulink mit vishia-Sfunction-Generator, Objektorientierung in Simulink.
2 Objektorientierung und Handleverbindungen im Modell - Details
Topic:.HdlPtrObjO.
Last changed: 2018-12-07
Das hier beschriebene Thema wird mit Simulink dargestellt. Es ist aber verallgemeinerbar auch auf andere Grafische Function-Block
Programmierumgebungen, die mit C/++ oder Java/C# zusammenarbeiten.
2.1 Objektorientierung bei der Modellierung
Topic:.HdlPtrObjO.ObjOCon.
Bei der Modellierung mit Simulink spielt die Objektorientierung oft keine Rolle. Die Modelle sind datenflussorientiert. Damit,
so könnte man meinen, sind sie sogar moderner: Es gibt eine Tendenz der Abkehr von der Objektorientierung hin zur Funktionalen
Programmierung, die ebenfalls die Sicht hin zur Eingabe/Verarbeitung/Ausgabe der Daten lenkt. Die Wahrheit liegt aber wie
oft eher in der Mitte. In der Softwaretechnologie hat die Objektorientierung als Herangehensweise ihren festen Platz. Kritik
an der Objektorientierung und Hinweis auf die Vorteile der Funktionalen Programmierung ist teils angebracht bei der Anwendungspraxis.
Soweit zur Einordnung der drei Paradigmen Objektorientierung, Funktionale Programmierung und Datenflussdarstellung.
Module enthalten mit grafischen Mitteln gezeichnet eine Reihe von Signalen, die in einem anderen Modul als Eingang möglicherweise
verwendet werden sollen. Wenn man diese alle als Einzelsignale herüberführt, dann entsteht das Chaos der Verbindungslinien.
Man kann im Tool Simulink Signale entweder als Bus oder als Kabelbünder (Multiplexer) zusammenführen. Dann kann aber schnell
der Überblick verlorengehen, welche Sigbnale dies sind.
Die Objektorientierte Herangehensweise bündelt in den objektorientierten Sprachen Daten mit ihren Operationen (in der Theorie
'Methoden' genannt). Auf die grafische Programmierung angewendet ist ein Modul eine (komplexe) Operation, und die Daten des
Moduls sollen gebündelt werden. Dazu sind die Busse in Simulink bedingt geeignet.
Der Verfasser hat mit Blick auf Datenstrukturen auch in der Realisierungsebene und dem Zugriff auf die Daten auch im Zielsystem
ein Set von Sfunctions als Simulink-Function-Block (FB) entwickelt, die sowohl Daten zusammenfassen, als auch diese Zusammenfassung
im Zielsystem beibehalten und mit einem sogenannten 'Inspector' sowohl im Simulink als auch auf dem Zielsystem zugriffsfähig
halten.
Die Objektorientierung in Simulink, eingeführt mit den S-Function Blocks DataStruct_Inspc und Out_DataStruct_Inspc und mit der Verwendung von C über Sfunctions verwendet Handle oder Pointer zum Datenaustausch, so wie es in der Implementierungsebene,
in Objektorientierten Sprachen wie C++ oder Java und in C üblich ist. Dem entgegen steht die traditionelle Orientierung auf
kopierende Weitergabe der Daten, die sicherer scheint aber jedenfalls an einigen Stellen auch Zeitaufwände im Ablauf im Zielsystem
mit sich bringt und an sich nicht notwendig ist. Die Verwendung von Referenzen ist von sich aus sicher. Ein Problem mit Pointern
gibt es nur bei Programmierfehlern, die in C und C++ nicht sicher abgefangen werden. Hier im Simulink werden sie abgefangen.
Ein sicherer Typtest erfolgt zur Startup-time beim Modelltest. Ähnlich wie in Java sind dafür alle Datenobjekte von einer
gemeinsamen Basisklasse abgeleitet die den Typtest unterstützt: ObjectJc (adäquat java.lang.Object). Das obige Video nennt diese Dinge ohne Blick auf den C-Code.
Das folgende Video zeigt, wie dies im Wrapper der Sfunction in C programmiert ist:
Dieses Video zeigt im Detail, wie Visual Studio ab 2015 mit 'Attache to process' mit Mathworks/Simulink zusammenarbeitet und
im einzelnen debuggt werden kann.
2.3 Vergleich und Herangehensweise - Datenverbindung mit Bussen oder Referenzen
Topic:.HdlPtrObjO..
Traditionell ist Simulink datenflussorientiert, Daten werden transportiert, nicht referenziert. Man kann zusammengehörige
Daten in Bussen zusammenfassen.
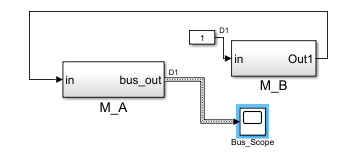
Das Bild zeigt zwei Module. Die Modularität ist außerhalb der Diskussion über Objektorientierung und Datenfluss ein unangefochtenes
Paradigma. Aber die Aufteilung der Funktionalitäten zu den Modulen wird von diffizilen Entscheidungen geprägt:
Ist es der Softwarearchitekt, der ein übergeordnetes Design bestimmt?
Hat der Softwarearchitekt Ahnung von den Details? Wie steht es mit der Anwendung agiler Prinzipien und Mitwirkung des Teams
und der einzelnen Bearbeiter?
Sollte nicht die Anzahl der Verbindungen minimiert werden, um die Modulgrenzen zu definieren? Damit würde der einzelne Modellierer
entscheiden.
Gibt es Wiederverwendung, Libraries?
Die Zurodnung der Funktionalitäten zu Modulen kann auch von der Aufteilung auf Bearbeiter (-Teams) bestimmt sein, einschließlich
einzelner Modultests (Unit-Tests).
Im Inneren des Moduls M_A befindet sich eine Teilschaltung, die mit einem Signal des M_B arbeitet. Verantwortlich für die
Teilschaltung ist Module M_A, dies soll so bleiben. Es soll aber aus diesem Teilmodell ein Submodul gebildet werden dass dann
im M_B eingesetzt wird. Grund für diese Intension: Das Inputsignal von M_B zu dieser Teilschaltung soll nicht als Modulschnittstelle
aufgenommen werden. Die Bildung dieses Signals soll eigenständig im M_B bearbeitet werden, ohne die Modulschnittstelle zu
beeinflussen.
Es ist aber auch entschieden, dass die Speicher für die Daten, die Unit-Delay-FB im M_A verbleiben sollen, aus Gründen des
Zusammenhalts von Daten. Solche Entscheidungen können auch getroffen werden, ohne an die Objektorientierung zu denken. Beispielsweise
soll offengehalten werden ob in der Weiterbearbeitung im M_A die Signale beispielsweise mit einer Reset-Logik versehen werden
oder ähnliches.
2.3.1 Busverbindung aus einem Modul M_A zu einer Operation zugehörig zu M_A in einem anderen Modul
Das Bild zeigt nun das Ausführungsergebnis: Das ehemalige Innenmodell ist in einem anderen Submodul M_B_2 untergebracht. Es
ist nun eine Verbindung für den Daten-Rückfluss notwendig.
Sieht man dies durch die Objektorientierte Brille, dann ist M_A_data nun das datenhaltende Modul aus M_A. Das fremde Modul
M_B enthält in seinem Inneren eine Operation, die zu M_A gehört. Ohne Objektorientierte Sicht ist dies das Ergebnis der Überlegung,
dass eine Datenverarbeitung von Daten aus M_A innerhalb eines anderen M_B_2 stattfinden soll. Objektorientierung kommt damit
ins Spiel, dass die Daten trotz Verarbeitung in M_B dennoch in M_A in den UnitDelays gehalten (gespeichert) werden sollen.
Das ist der Kerngedanke der Objektorientierung: Bündelung von Daten, relativ unabhängige Operationen ('Methoden') mit den
Daten. Die Operationen oder 'Methoden' gehören zu den Daten. Ohne Objektorientierung ist der Treiber die Verantwortung für
die Datenverarbeitung, die zum Modul M_A bzw. zu dessen Library gehört, dass eventuell ein Wiederverwendungskandidat ist.
Die Objektorientierung formuliert dies nur systematischer.
Das rechtsstehende Bild zeigt die eigentliche M_A_Operation, die zum Modul bzw. zur Library M_A gehört aber in M_B verwendet
wird.
Die Lösung ist aber insgesamt wegen der Rückverbindung nicht sehr elegant. Diese ist als Bus ausgeführt schon noch übersichtlich.
Jedoch muss bedacht werden, dass dies ein einfaches Beispiel ist. Gibt es mehreren M_A_operationXY in verschiedenen Modulumgebungen,
dann braucht es jeweils angepasst Teil-Busse mit Rückschreibe-Daten nach A. Die Datenlieferung (MA_data) kann jedoch als ein
Bus ausgeführt werden, aus denen sich das jeweils nutzende Modul die passenden Daten herauszieht.
2.3.2 Alternative: Referenzierung
Topic:.HdlPtrObjO...
In der Objektorientierung und in der gesamten ablauforientierten Datenverarbeitung spielen referenzierte Daten eine sehr große
Rolle. Daten werden im Maschinencode eigentlich immer referenziert, auch lokale Variable stehen, wenn die Prozessorregister
nicht ausreichen, referenziert über das SP-Register im Stack.
In C gibt es die 'Pointer' mit einem schlechten Ruf. Pointer sind Referenzen: Die Verwendung von Referenzen ist von sich aus
sicher. Ein Problem gibt es nur bei Programmierfehlern, die in C und C++ nicht sicher abgefangen werden. Hier im Simulink
werden sie abgefangen. Ein sicherer Typtest erfolgt zur Startup-time beim Modelltest. Ähnlich wie in Java sind dafür alle
Datenobjekte von einer gemeinsamen Basisklasse abgeleitet die den Typtest unterstützt: ObjectJc (adäquat java.lang.Object).
Referenzen können in Simulink über S-Functions gebildet werden. Sie passen in eine uint32-Variable, wenn sie in einem 64-bit-System
als Handle gehandelt werden und über passende Mechanismen intern in die notwendige 64-bit-Speicheradresse umgesetzt werden. Für ein
32-bit-Zielsystem reicht dann das unit32-Format als Adresse direkt. Dies ist kein numerischer Wert, sondern ein Wert, der
nur weitergereicht wird. Im Simulink erfolgt eine Eingangskontrolle der Speicheradresse. Ähnlich wie in Java wird zur Startup-Zeit
oder auch zur Laufzeit bei wechselnden Adressen die Richtigkeit des Typs getestet. Das ist in TODO näher ausgeführt.
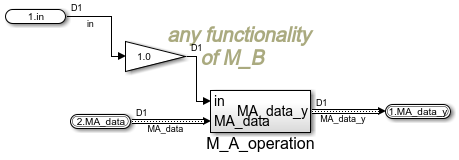
Das Bild zeigt die gleiche Funktionalität wie Bild 'Submodul im M_B'. Der Rück-Bus ist entfallen, die Modulverbindung ist
nicht mehr mit einem Bus ausgeführt sondern mit einer Handleverbindung.
Nach dem Datenfluss-Paradigma, dass den FBlock-Darstellungen im Simulink eigen ist, ist folgende Interpretation zulässig:
Modul M_A liefert als Datenfluss die Referenz der Daten aus M_A dem nutzenden Modul M_B. Innerhalb des M_B kann dann mit den
Daten gearbeitet werden.
Das Bild ist das adäquate Bild wie im Vorabschnitt, nur das hier das Handle die Verbindung darstellt und der Rückdatenfluss-Bus
entfällt. Es ist nun die Eingenschaft des M_A_operation als Operation auf die Daten MA_data gut zu erkennen. Die MA-Data werden
als 'this'-Referenz geliefert, weitere Ein- und mögliche Ausgänge stellen die weiteren Schnittstellen der Operation dar. Die
Operation enthält keine eigene Datenhaltung, also keine Unit-Delay oder dergleichen. Damit ist auch die Charakteristik für
den Ablauf im Zielsystem (des Zielsystem-Machinen- oder C-Codes) abschätzbar.
Das entspricht dem Folgebild im Vorabschnitt, das Innenmodell des M_A_operation. Statt dem BusSelektor und dem BusCreator
sind zwei Sfunctions für den Datenabgriff und das Datensetzen verwendet. Das sind allgemeine Module aus der lib_Inspc die mit den Variablen parametriert wurden, keine direkt in C zu schreibenden und selbst zu erstellenden Sfunction. Damit
sind dies sogenannten getter und setter als direkten Zugriff auf die Daten. Es werden aus den Gesamtdaten des Modul M_A aber nur diese Teildaten gesetzt, ohne dass
ein extra Aufwand (der Rückdatenfluss-Bus) notwendig ist.
Man kann an diesen Stellen auch manuell geschriebenen C-Code einbinden, beispielsweise um betriebsspezifische Datenkonsistenzoperationen
einzubinden. Ein allgemeiner Datenkonsistenzansatz, die Verwendung eines Wechselpuffermechanismus wie er an solchen Stellen
oft üblich ist, dann von entsprechend spezialisierten allgemeinen Modulen aus lib_Inspc erwartet werden.
3 Links zu zusammengehörigen Themen - Implementierung in Simulink
Topic:.ImplSmlk.
Das Thema der Objektorientierung in Grafischer Programmierung ist konkret in Simulink gestaltet und getestet. Die folgenden
Links beziehen sich auf Simulink und die entsprechenden Testbeispiele:
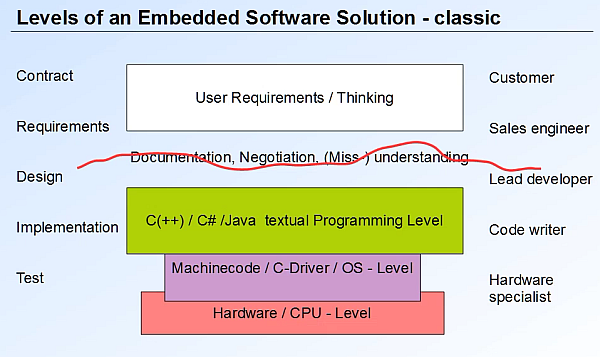 Bild: Kunde-Entwicklung Missverständnisse
Bild: Kunde-Entwicklung Missverständnisse