Die grafische Programmierung für Anwendungen der Embedded Systeme (Geräte- und Anlagenprogrammierung) ist Jahrzehnte nach
Einführung grafischer Programmierwerkzeuge zumindestens in der Geräteentwicklung noch nicht angekommen. Aus der Intension
heraus, die Kernfunktionen müsse man Prozessor-nahe in C programmieren und die Betriebssystemanbindung ist C, wird die gesamte
Applikation häufig in reinem Quelltext in C oder C++ ausgeführt. Dabei hilft die UML bei der Softwarestrukturierung, doch
selbst der UML-Einsatz ist differenziert.
Das Problem könnte in mangelnden Standards, und nicht kompatiblen Tools liegen.
Die hier gezeigten Lösungsansätze möchte folgenden Herangehensweise vorschlagen:
Tools dürfen verschieden sein. Insbesondere die Grafische Programmierung mit FunctionBlock ('FBlock')--Darstellung wie Simulink
oder Modelica hat häufig den Simulationshintergrund, es gibt verschiedene Domänen.
Die Codegenerierung aus den Tools sollte vereinheitlicht werden. Es wird eine textuelle Zwischensprache, die FBCL = Function
Block Connection Language für FunktionsBlock-Grafiken vorgeschlagen. Die textuelle Form ermöglicht den Versionsvergleich und
eine von der Grafik abstrahierte Funktionsbeschreibung.
Alle Vorteile der UML wie einheitliches Repository, Traceablility von Requirements etc. sollen bedacht sein.
Es gibt eine Norm für Automatisierungs-Programmierung: IEC61131 und darauf aufbauend 61149. Die Automatisierungsprogrammierung
folgt in Teilen dem FBlock-Grafiken-Prinzip. Eine Textnotation ist in der IEC61131 mit ST (Structure Text) genormt. Die IEC61449
regelt zusätzlich das auf Einzelgeräte verteilte Deployment aus einem Plan mit Eventsteuerung. Diese Normen sollen in die
Überlegung mit einbezogen werden.
Die Inhalte auf dieser Seite sind experimentell. Es handelt sich nicht um bereits fertig einsetzbare Lösungen, sondern um
eine Zielrichtung der Entwicklung, die im Moment in Diskussion ist. Der Artikel wird entsprechend dem Arbeitsstand erneuert.
Stand 2019-05-07
1 Nachteil von Quelltextprogrammierung in C(++) und UML
Topic:.FBG_UML_norm.UMLdisadv.
Last changed: 2019-03-15
Es sind in den letzten Jahren einige neue C++-Standards erschienen, die eine immerwährende Verbesserung versprechen. Der erste
Nachteil der Quelltextprogrammierung wird dadurch aber nicht behoben: Die Programme sind nur von Experten zu durchschauen.
Die Implementierung kann von den Requirements, genauer gesagt von den Vorstellungen der Kunden, Anwender und Applikationsingenieure
abweichen, ohne dass dies bewusst und ersichtlich ist.
Seit längerer Zeit ist dafür die UML in der Pflicht: „Unified Modelling Language“ mit 14 Diagrammarten, der Möglichkeit der
Anforderungsverfolgung in einem Repositiory vom Entwurf in einem beispielsweise Use-Case-Diagramm bin hin zu der implementierenden
Operation im Class-Diagramm, automatischer Dokumentationsgenerierung usw. usf. Von der UML-Lobby wird nun beklagt, dass diese
doch so durchgängige und auch standardisierte Herangehensweise zu wenig benutzt wird. Die grafische Programmierung sei immer
noch nicht angekommen.
Die UML ist eine wesentliche Größe in der Software-Technologie. Gerade weil sie „Unified“ ist, nicht toolspezifisch sondern
übergreifend jedem geläufig. Auch weil eine Übersicht in einem ObjectModelDiagram wichtig ist zur Erkennung und Verbesserung
der Softwarestruktur der Datenzusammenhänge. Aber die UML definiert eigentlich jeweils nur die Rahmen der Programme (außer
den State-Diagrammen, diese sind konkret).
2 Grafische Programmierung mit Funktionsblöcken und Datenfluss
Topic:.FBG_UML_norm.FBgraph.
Last changed: 2019-04-16
Die Welt der grafischen Programmierung mit Tools wie Mathworks-Simulink, Simplorer, Labview, Modelica und vielen anderen Spezialtools
spielen eine eigene Rollen neben manueller odr UML-gestützter Programmierung. Es gibt eine „Unified Modelling“- Welt, die
aber hier unterstellt wirkliche Grafische Programmierung nicht schafft, und eine „Diversity Modelling“- Welt deren Anwendungsansätze
sich zwar grundsätzlich unterscheiden, jedes Tool hat seine eigenen Ansätze und Clientel, aber die Diagramme für codegenerier-relevante
Modellteile sind irgendwie ähnlich.
Verbindend für diese Tools ist das Zeichnen von Funktionsblöcken, die miteinander als Datenfluss verbunden sind. Alle diese
Tools können mittlerweile die Codegenerierung für die embedded Software, aber jeweils spezialisiert. Die Daten der Modelle
sind kaum oder nicht austauschbar.
Ein wichtiger Vertreter dieser anderen nicht-UML-Welt ist die Automatisierungsgeräteprogrammierung. Diese tritt mit Standards
wie IEC61131-3 oder dem darauf aufbauenden IEC61449 zwar von vielen Herstellern, aber mit gemeinsamen Ansatz auf. Dabei spricht
die Verbreitung und Bedeutung der Automatisierungsprogrammierung nicht für ein Nischendasein. Im Gegensatz zu anderen Tools
ist die Automatisierungsgeräteprogrammierung standardisiert und über weite Teile kompatibel. Die FunctionBlockDiagram-Darstellung
(FBD) ist hier ebenfalls präsent.
Wenn sich ein Anwender nun für eines dieser Tools der FunctionBlock-Grafik entscheidet, dann ist dies zumeist eine tiefgreifende
und bindende Investition. Man gewöhnt sich an die Eigenheiten 'seines' Tools, wenn etwas nicht geht, dann wird das akzeptiert
und an dieser Stelle möglicherweise manuell programmiert. Wenn die Nachbarabteilung oder der neue Geschäftspartner auf ein
anderes Tool setzt, dann spricht man verschiedene Sprachen. Immerhin gibt es zwar bei fast allen Simulationstools eine 'dll-Schnittstelle',
mit der man vorcompilierte Teile einer Simulation in andere Tools zu einer Gesamtsimulation zusammenbauen kann. Damit können
verschiedene Gewerke gut zusammenarbeiten. Das ist auch gut und richtig, denn das Knowhow der Simulation, tatsächlich oft
notwendigerweise an ein Tool gebunden, ist für verschiedene Bereiche unterschiedlich angesiedelt.
In diesem Artikel geht es dagegen um eine einheitliche Herangehensweise für die Grafische Programmierung allein für die Codegenerierung
von Embedded Anwendungen. Wird ein Simulationstool für das Gesamtsystem, nicht nur für die codegenerier-relevanten Teile eingesetzt,
dann hängt diese Codegenerierung sozusagen hinten-an, geht auch mit. Damit bedingt aber die Spezialisierung im Simulationstooleinsatz
die Inkompatibilität in der Grafischen Programierung.
Im Abschnitt Chapter: 6 Objektorientierung in der Funktionsblock-Grafik vs. Datenfluss vs. funktionaler Programmierung wird darauf hingewiesen, dass auch bei FBlock-Grafiken die Objektorientierung eine Rolle spielen sollte. Bereits damit ist
man mindestens in der Nähe der UML, denn eine FBlock-Grafik mit Handle-Datenverbindungen kann formell in ein ObjectModelDiagram
der UML überführt werden. In den FBlock-Grafik-Tools fehlt oft einiges, was die UML auszeichnet. Als Stichwort sei hier nur
Traceablility von Anforderungen genannt. Für die Verbindung der FBlock-Toolwelt mit der UML gibt es Ansätze, die verfolgt
werden sollten. Sie sind jedoch hier nicht im Fokus.
4 Darf's noch etwas komplizierter sein
Topic:.FBG_UML_norm.complex.
Last changed: 2019-04-16
Dies ist kein einseitiger Vorwurf an die Informatiker oder Mathematiker. Unsere heutige Denkweise tendiert dazu, für den Endanwender
es ganz einfach zu machen. Was innen abläuft, ist dann hochkomplex nur für Experten. Philosophisch betrachtet: gefährlich.
Praktisch betrachtet: falsch.
Die Automatisierungsprogrammierung soll von je her vom eher elektrisch gebildeten Inbetriebsetzer verstanden werden. Es ist
einfach zu durchschauen, dass zwei Signale gleichzeitig anstehen sollen, damit es losgeht, also ein AND. Ein Flipflop hört
man fast klacken, auch wenn es nur grafisch dargestellt ist, es hat genau zwei Zustände, ... um es etwas narrativ darzustellen.
Interessant dabei ist, dass das Denken in State-Diagrammen durchaus in dieses Schema hineinpasst. Bei einem State weiß man
wo man ist und wann gewechselt wird. Auch die etwas komplexeren State-Diagramme der UML (nach David Harel) sind verständlich.
Es wäre nun fatal für die Automatisierungswelt, wenn dieses überschaubare Software-Engineering zugekippt wird von dem in Wirklichkeit
sehr widersprüchlichen Software-Engineering außerhalb der Automatisierungstechnik, nur weil die Ablaufhardware (Industrie-PCs,
Raspberry-Pi, Hochleistungs-Embedded Prozessor-Boards) an der Edge der Cloud den Automatisierungsgeräten auf die Pelle rücken
und versuchen diese zu vertreiben (ersetzen).
Das Problem der Programmierung mit diversen meist textorientierten Systemen (C++) in der Edge ist: Die Programminhalte sind
nicht direkt ersichtlich. Es sind Experten, Reviewer, Aussagen über Tests notwendig für eine Verlässlichkeit. Zweites Problem
ist die Diversität der Systeme. Programme nach IEC61131 können zwar auch komplex sein, sind aber direkt nachvollziehbar.
Das Problem, das hinter dieser etwas polemischen Wortwahl steckt, ist: Software muss durchschaubar sein, und zwar nicht nur
vom Experten Softwareentwickler und Softwareprüfer (SIL, Abnahmeprüfung etc), sondern auch vom Betreiber, Endanwender, Experte
beim Kunden. Nur so sind Denkfehler, der letztlich auch zu bedeutenden Unfällen führen können, frühzeitig erkennbar. Alle
relevanten Personenkreise müssen mitmischen können.
Wenn ein einzelner Messwert eine Software unkontrolliert funktionieren lässt, und die Möglichkeit des manuellen Abschaltens
dieses Softwareteils wurde unzureichend dokumentiert oder geschult, weil wahrscheinlich die Prüfer eines bedeutenden Flugzeugherstellers
dies übersehen hatten (dies sei nur ein Beispiel), dann wäre dies mit einer durchschaubaren Softwarestruktur irgendwo im größeren
Personenkreis vielleicht auffällig geworden. Nicht zuletzt ist der anerkannte Siegeszug der Open-Source-Bewegung mit der breiten
Kenntnis der Quellen ein Beweis, dass nicht Expertentum, sondern die Allgemeinheit den besseren Beitrag leistet. - Dennoch
darf Software closed sein, in bestimmten Bereichen, dies nur als Ergänzung bemerkt, aber in diesen Bereichen auch von einem
größeren Personenkreis durchschaubar.
5 Vergleich der Funktionsblockdarstellung in Simulink und IEC61449 am Beispiel
Topic:.FBG_UML_norm.cmpGraph.
Last changed: 2019-04-10
Die Tools der Grafischen Funktionsblock/Datenfluss-Programmierung haben keine Zwischensprache. Die Zielsprache ist meist C(++),
passend für die Anwendung im Embedded Bereich. Genau daher sind diese Tools aber immer spezifisch, spezialisiert, nicht austauschbar.
Schaut man auf eine Grafik die mit Simulink realisiert ist, dann kann man diese mit gleicher Funktionalität auch beispielsweise
nach der Norm IEC61449 realisieren, hier dargestellt im Open-Source 4diac-Editor:
Es kommt nicht darauf an, welches Tool das bessere wäre. Vielmehr ist man jeweils in seiner Domäne orientiert. In der Domäne
wird aber eigentlich Vergleichbares realisiert:
Die Unterschiede zwischen dem Simulink-Diagramm und dem IEC61449-FBD sind eher formaler Natur bzw. sind Detailunterschiede.
Auffälling sind jedoch in FBD die Eventverbindungen. Die meisten davon sind einfache Folgeketten, die eigentlich nur die Abtastreihenfolge
verbinden.
Im Simulink dürfen Abtastzeiten gemischt in einem Diagramm auftreten. IEC61449 regelt dies ebenfalls mit den Eventketten.
So ist hier deutlich die Initialisierungsabfolge erkennbar. Im Simulink ist der Inport par der Tinit-Abtastzeit zugeordnet und der FBlock PIDctrl hat sogenannte port-based-Abtastzeiten. Damit gibt es auch dort eine Initialisierungsphase, aber im Diagramm nur dann zu erkennen, wenn die Abtastzeiten
dargestellt werden.
Bild: 4Diag. In der 4diac-Darstellung des pidCtrl-FBlock-Interfaces ist grafisch zu erkennen, dass der Eingang par dem INIT-Event zugeordnet ist.
6 Objektorientierung in der Funktionsblock-Grafik vs. Datenfluss vs. funktionaler Programmierung
Topic:.FBG_UML_norm.ObjO.
Last changed: 2019-04-10
Die Objektorientierung ist ein Begriff, der zuerst mit C++ (auch Java, C#) in Verbindung gebracht wird und unter dem man sich
Vererbung, Abstraktion vorstellt, manchmal auch mit dem Templatekonzept in C++ in einen Topf wirft. Objektorientierung für
sich genommen ist aber vordergründig 'nur' die Betonung der Sicht auf die Daten, anstelle der Sicht auf den Programmablauf.
Abstraktion, Vererbung und Interfaces sind eine darauf aufbauende sinnvolle aber nicht notwendige Technik. Objektorientierung
bedeutet also im Kern, dass Operationen (Prozeduren, in C „Funktionen“) an Daten direkt gebunden sind. Die Operationen operieren
mit den Daten und werden akademisch auch „Methoden, die auf die Daten angewendet werden“ genannt. Der Begriff Operation ist
schlüssiger und wird auch im UML-Umfeld verwendet.
Man kann in der Funktionsblock-Datenfluss-Grafik objektorientiert arbeiten: Ein Block ist für die Daten verantwortlich. Der
Zugriff auf die Daten als Referenz oder Handle wird als Datenfluss einem anderen Block weitergegegen, der dann mit diesen
Daten operieren kann. Der andere Block ist eine Operation auf diese Daten, wenn er keine eigenen Daten enthält, oder es handelt
sich um eine Assoziation (Aggregation im UML-Sinn) auf referenzierte Daten. Der Zugriff auf die Daten kann lesend und schreibend
erfolgen. Letzteres durchbricht scheinbar das Datenflussprinzip, weil der Zugriff auf die referenzierten Daten quasi rückwärts
erfolgen kann. Dieses Prinzip wäre dem rein datenflussorientiert denkendem etwa Regelungsentwickler womöglich nicht geläufig
(oder geheuer), entspricht aber dem bekannten Paradigma aus UML und objektorientierter Welt.
Die Objektorientierung hat ganz stark mit Modularität zu tun: Ein Modul enthält eine Funktionalität, wozu es Daten braucht.
Dieser Sachzusammenhang ist außerhalb der Informatiker-Welt, also dem Automatisierungs-Programmierer, durchaus klar.
Daher ist für eine Funktionsblock-Grafik dieses objektorientierte Prinzip eigentlich eine angemessene oder auch dringend gebotene
Erweiterung, in aktuellen beispielsweise Simulink-Versionen so nicht vorzufinden. Die bewährte OO-Technologie wird auch für
diese grafischen Modelle appliziert.
Für Simulink gibt es vom Verfasser eine Entwicklung zur Objektorientierten Modulierung /SmlkOO/. Für Modelica ist adäquates
in Arbeit. Für Simatic-FUP ist im TIA-Portal die Objektorientierung bereits angekommen. Instanzdatenbausteine sind von je
her ein Ausdruck der Objektorientierung. Für Details siehe auch /TIAOO/ und /SimOO/.
Im Beispiel ist der Eingang par im Simulink-Diagramm ein Handle der Objektorientierten Grafik, im FUP ist es ein Eingang mit
einer UDT-Definition (User Data Type). Das entspricht im Simulink zwar eher einem Bus, bewirkt hier aber das gleiche: Bereitstellung
der Parameterdaten als Aggregation.
6.1 Funktionale Programmierung
Topic:.FBG_UML_norm.ObjO.fnprg.
Last changed: 2019-03-15
Wenn von objektorientierter Programmierung die Rede ist, sollte der Verweis auf das Gegenparadigma, die Funktionalen Programmierung,
nicht fehlen. Insbesondere deshalb, weil die Datenflussorientierung eher der Funktionalen Programmierung entspricht. Die Funktionale
Programmierung wird akademisch diskutiert und verwendet. Es wird bewusst auf Datenspeicherung verzichtet (daher 'Gegenparadigma'):
Ein Ausgang ist das Funktionsergebnis der Eingänge, wie bei einer mathematischen Funktion. Datenspeicher werden mit dem Ergebnis
der Funktion dann jeweils neu gebildet. Dabei kommen Konstrukte heraus, die praktisch schwieriger zu behandeln, aber weniger
fehleranfällig sind: Einer objektorientierten Operation sieht man nicht an, welche Daten sie beeinflusst. Dies sei der Vollständigkeit
erwähnt. Dennoch ist die Formel Modularität = Objektorientierung praktisch gut. Man sollte nur nicht einen Wildwuchs an Daten
bauen, und insoweit an das Paradigma der Funktionalen Programmierung denken.
7 Eventsteuerung und Rechenzeitreihenfolge in Quelltext, Simulink und IEC61149
Topic:.FBG_UML_norm.ev.
Last changed: 2019-04-10
Im anweisungsorientierten Quelltext ist die Rechenzeitreihenfolge selbstverständlich die Anweisungsreihenfolge. Bei Eventsteuerung wird die Sache schon komplexer
und teils spezifisch:
Es gibt Routinen, die Events zugeordnet werden, sogenannte Callback-Routinen. Das ist gängige Praxis bei Grafiksystem-Programmierungen
(GUIs) oder etwa Java-Script.
Es gibt die Routinen, die in Statemachines bei Transitions und Entry/Exit-Actions aufgerufen werden. Diese sind Teil der Statemaschine..
Möglicherweise gibt es auch einen handgeschriebenen Dispatcher, der beim Ausräumen der Eventqueue je nach Eventtyp bestimmte
Routinen aufruft.
In grafischen FBlock-Programmierungen ist man grundsätzlich zweidimensional unterwegs. Damit stellt sich die Abarbeitungsreihenfolge
als wesentlich. Einige Systeme (beispielsweise STRUC für Simadyn aus den 1990-gern, Siemens-AG) hat dies mit einer Reihenfolge-Nummer
geregelt. Der Anwender war damit direkt für die Reihenfolge verantwortlich, und eine Verwechslung hat das Auftreten von Totzeiten
zur Folge, weil die Datenbereitstellungsreihenfolge nicht stimmt.
7.1 Simulink
Topic:.FBG_UML_norm.ev.smlk.
Last changed: 2019-04-10
Daher ist man bei Simulink, auch Modelica besser aufgestellt, indem die Abarbeitungsreihenfolge vom Datenfluss bestimmt wird.
In entsprechend aufwändigen Analysen des Modells wird beim Simulationsablauf und bei der Codegenerierung die Reihenfolge aufgrund
der Datenverbindungen festgestellt. Es gibt dann die Fehlermöglichkeit der numerischen Schleife, wenn man im Berechnungskreis im Modell nicht bewusst ein unitdelay eingebaut hat. Es gibt verschiedene Abtastzeiten, abtrennbar mit einem Rate transition-FBlock. Der Datenfluss jeder Abtastzeit wird getrennt bewertet. Ports, die einzelnen Anschlüsse an FBlocks, können abtastzeitspezifisch
sein (port-based sample time).
Man sieht aber durch Anschauung der Grafik nicht direkt die Rechenzeitreihenfolge, sondern muss sich auf die Richtigkeit des
Datenflusses verlassen. Hat man hier Fehler eingebaut, dann ist "Fehlersuche angesagt". Mit entsprechenden Display-Einstellungen
kann man zwar eine sorted execution order einschalten, dies ist aber nicht immer hilfreich.
Bei Simulink gibt es insbesondere im Zusammenhang mit Statemachine-Realisierungen das Triggered Subsystem. Die besondere Triggerverbindung eines FBlocks, der typischerweise 'composite' sein kann, also als Submodul wieder FBlocks
enthält, wird von Stateübergängen ausgelöst. Es gibt auch das Enabled Subsystem mit einem boolean-Eingang der Freigabe
7.2 FBD nach IEC61131-3
Topic:.FBG_UML_norm.ev.IEC61131.
Last changed: 2019-04-18
In den FBlock-Diagrammen der IEC61131 regelt eine Hauptverbindung, die bei komplexen Blöcken jeweils ENO des Vorgängerblocks und EN des Folgeblocks verbindet, die Rechenzeitreihenfolge. Die ENO-EN-Verbindung hat gleichzeitig die Funktion der Freigabe (ENable und ENableOut). Bei etwa einem numerischen Fehler wird ENO=0 gesetzt und der folgende Block wird erst gar nicht abgearbeitet. ENO kann in boolean-Verknüpfungen einbezogen werden und damit zur Fehlermeldung, einem Sperrsignal und dergleichen führen. Diese
Art Ausnahmebehandlung, hier sehr einfach realisiert, fehlt beispielsweise im Simulink. Es ist dort anwenderfrei und damit
nicht genormt, wie in solchen Fällen verfahren wird.
Die Abtastzeiten sind nach IEC61131 dagegen nur sehr restriktiv handhabbar: Ein FBlock darf nur eine Abtastzeit haben, zusätzlich
zur Initialisierung mit Defaultwerten, aber ohne Algorithmus. Man muss für verschiedene Abtastzeiten also verschiedene FBlocks
anlegen. Wenn diese dann auf die gleichen Daten arbeiten sollen, beispielsweise weil eine Parameterberechnung für einen Regelalgorithmus
seltener durchlaufen werden soll als der Regelalgorithmus selbst, dann wird es meist handgestrickt. Man greift in solchen
Fällen oft von einem FBlock direkt auf die Daten des global angeordneten oder über Pointermechanismen erreichbaren Daten des
anderen FBlock zu. Die IEC61131-3 ist insgesamt mittlerweile etwas veraltet. Eine globale Herangehensweise an Daten ist zwar
auch in C immer noch üblich, jedoch eigentlich spätestens seit Verbreitung der Objektorientierung nicht mehr ganz hoffähig.
7.3 IEC61449
Topic:.FBG_UML_norm.ev.IEC61449.
Last changed: 2019-04-18
Die IEC61149, die die FBlock-Darstellung der IEC61131 aufgreift und erweitert, geht einen konsequenteren Weg:
1) Statt der einfachen ENO-EN-Verbindung gibt es Eventketten. Die Abarbeitung ohne interne Statemachine ist den Input-Events zugeordnet.
2) Ein FBlock kann mehrere Event-Inputs haben, und damit mehrere Abtastzeiten. Die Ports (Connections) sind den Events zugeordnet,
wobei eine Mehrfachzuordnung möglich ist. Das ist in etwa vergleichbar mit den port-based sample times des Simulink. Auch dort kann ein Input in einer anderen Abtastzeit benutzt werden als die im direkt zugeordnete. Das ist
dort aber formal undokumentiert.
3) Die FBlocks können grundsätzlich immer Statemachines enthalten. Diese können Events annehmen und aussenden. Zu den States
sind ALGORITHM zugeordnet, das sind Structure-Text-Anweisungsfolgen nach IEC61131-3, die Daten entsprechend verarbeiten. Wird bei einem
Stateübergang ein Event erzeugt, dass in anderen FBlocks über Eventketten nicht einen Stateübergang triggert sondern 'nur'
zur Abarbeitung des Blocks führt nach 1), dann sind die damit verbundenen ALGORITHM eigentlich dem Stateübergang hinzuzurechnen.
4) Die Eventketten können geräteübergreifend ausgeführt sein: Ein Gesamt-FBlock-Diagramm für das System wird in Geräte zugeordnet (deployed). Dabei spielen Überlegungen, welches Signal in der Anlage wo angeschlossen ist, die größere Rolle als etwa Überlegungen
der Rechenzeitverteilung. Ist ein Endschalter an Maschine A vorhanden, nimmt selbstverständlich die zugehörige Automatisierungssteuerung
in der Nähe das Signal auf. Wenn dann Maschine B anlaufen soll, wird das Event auf das zugehörige Automatisierungsgerät übertragen.
5) Die Abarbeitungsreihenfolge wird damit ausschließlich von den Events bestimmt. Es gibt selbstverständlich eine Parallelität,
da mehrere Events in einem Schritt erzeugt werden können. Wird die Abarbeitung von Gerät A auf Gerät B angestoßen, muss also
nicht Gerät A warten. Sicherlich hat Gerät A noch ein anderes Event zu verarbeiten. Die Rechenauslastung muss dann eine Rolle
spielen, wenn man in schneller Echtzeit mit aufwändigen Algorithmen unterwegs ist. Das muss dann bei der Eventaufteilug berücksichtigt
werden.
6) Wenn zwei FBlocks per Event-Kette direkt verbunden sind und auf dem selben Gerät angesiedelt sind, dann ist das die Rechenzeitreihenfolge.
Dieser Fall ist durchaus typisch, wenn eine Funktion rein aus Ordnungs- und Übersichtsgründen auf mehrere FBlocks verteilt
wird.
7.4 Überlegungen zu typischen Spezialfällen der Eventketten in der IEC61149
Topic:.FBG_UML_norm.ev.ev.
Last changed: 2019-04-10
Diese Überlegungen sind nicht in jedem Fall korrekt und zur Diskussion / Korrektur bestimmt.
7.4.1 Event wirkt eigentlich nur als Abarbeitungsreihenfolge-Bestimmung
Topic:.FBG_UML_norm.ev.ev.calcOrder.
Last changed: 2019-04-18
Im Vorkapitel ist im Punkt 6) bereits ein Spezialfall benannt: Ein Simple-FBlock enthält nur je ein Input- und Output-Event und keine Statemachine. Das entspricht dem FBlock nach IEC61131-3, das Output-Event,
vergleichbar mit dem ENO, ist aber hier nicht auf 0 setzbar. Es kommt zwangsläufig immer, wenn der FBlock aufgrund des Input-Event abgearbeitet wird.
In diesem Fall ist das eine reine CalculationOrder-Bestimmung.
Ein Simple-FBlock mit mehreren Events scheint es in IEC61449 nicht zu geben (?). Wenn vorhanden, dann wäre das ein FBlock,
der Algorithm für verschiedene Eventketten, mithin für verschiedene Abtastzeiten enthalten könnte. Das wären quasi eine Zusammenfassung
mehrerer Simple-FBlock, die aber auf die gleichen Daten arbeiten. Es wäre wünschenswert, dies zu haben.
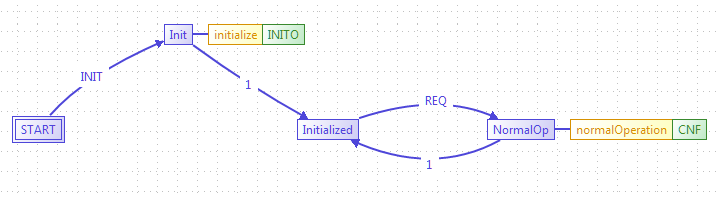
Ein Basic-FBlock, der nur eine sehr einfache Statemachine enthält, die lediglich Initialisierung und Abarbeitungsschritt berücksichtigt,
sieht wie folgt aus:
Auch hier gilt die Regel: CNF kommt immer nach REQ. Wenn man voraussetzen darf, dass die Initialisierung erledigt ist, sich also alle solche FBlocks im Zustand Initialized befinden. Das lässt sich verifizieren mit Abfangen des letzten INITO in der INIT-Kette. Damit ist auch hier die Eventkette lediglich die Abarbeitungsreihenfolge.
In einer allgemeinen Implementierung würde jedes Event, unabhängig von den obigen Überlegungen in einer EventQueue gespeichert.
Das Ausräumen der Eventqueue bestimmt dann die Abarbeitung. Das funktioniert. Wenn aber der IEC61149-Quellcode für allgemeine
Embedded Lösungen herangezogen wird, wie dies im Kapitel Chapter: 9 Erarbeitung der Syntax der funktionalen textuellen Repräsentation von FBlock-Diagrammen vorgestellt wird, dann ist diese Implementierung im Bereich schneller Abtastzeiten (50 µs) mit Laufzeiten eines FBlock im
ns-Bereich uneffektiv. Der Einsatz der direkten abtastzeitbestimmenden Eventverschaltungen ist der typische Fall, um Algorithmen
grafisch zu implementieren. In der Codegenerierung sollte dann direkt die Abarbeitung hintereinander erfolgen. Verwendet man
in der Implementierungsebene in C(++) inline dann ist man auch bei sehr kurzen Algorithmen pro FBlock (ein F_ADD, F_MUL etc) sehr schnell. Diese Grundelemente können auch zweckmäßigerweise, aber erst auf der Ebene der Implementierungs-Codegenerierung,
als komplexe Expression geschrieben werden.
Es wäre nun hilfreich, in der Quelltextdarstellung nach IEC61449 am Event eine Zusatzinformation zu sehen, dass CNF unbedingt direkt nach REQ folgt, um die Codegenerierung entsprechend zu gestalten. Die Analyse der internen Statemachine bringt zwar diese Information
ebenfalls, es ist aber dazu ein Zusatzschritt notwendig.
Eine Statemachine, die für diesen Einfachfall zwei Abtastzeiten unterstützt, sieht wie folgt aus:
Diese Statemachine wäre das Muster für die typische Abtastzeitgestaltung. Neben init ist nun auch ein terminate-Event eingeführt, dass in der Implementierung dann ebenfalls über eine Eventkette termO->term die Terminierung der Initialisierung ausführt (Herunterfahren, de-Initialisieren).
Die States haben hier nur die Bedeutung, zu verhindern, dass die Abarbeitung nicht ohne Initialisierung ausgeführt werden
kann. Das wäre in einer manuellen Implementierung ein bit isInititialized. Ansonsten werden die Events immer weitergereicht.
7.4.2 Event kann die Abarbeitung abbrechen, Fehlerfallbehandlung wie ENO in IEC61331-3
Topic:.FBG_UML_norm.ev.ev..
Last changed: 2019-04-18
Die Variante in IEC61131-3 mit dem Disablen der weiteren Abarbeitung über ENO ist in der Automatisierungstechnik durchaus weit verbreitet. Es ist ein einfaches und wirkungsvolles Muster. Es soll nun
im folgenden gezeigt werden, wie das auch in IEC61449 kompatibel erfolgen kann und welche Codegenerierung dazu gehören könnte.
Das ENO-Event wird nicht unbedingt ausgesendet, sondern nur wenn die Abarbeitung nicht in einen Fehlerfall geht. In der rechtsstehenden
Statemachine ist das nicht eindeutig gekennzeichnet, der Übergang muss ohne Event nur mit einer Bedingung erfolgen. Oder das
Event muss direkt im ST-Code erzeugt werden, damit ist es aber nicht mehr in der übersichtlichen Statemachien sichtbar sondern
verschwindet sozusagen im Textcode, weniger günstig für die Doku.
Auch bei Auftreten des Fehlers wird wieder in den initialized-State zurückgekehrt. Der Fehler wird nicht gespeichert sondern beim folgenden EN-Aufruf aus den Daten wieder erneut detektiert oder ist eben nicht mehr da. Dieses Verhalten entspricht den FBlock nach IEC61131-3.
Es gibt allerdings einem Unterschied: In IEC61131-3 ist ENO ein BOOL-Ausgang und kann für die Logikverknüpfung benutzt werden,
insbesondere um den Fehler anzuzeigen. Das widerspricht aber der Event-Strategie. In der rechts-oben stehenden Statemachine
ist stattdessen ein zweiter Event-Ausgang ENON vorgesehen, der den Fehlerfall anzeigt. Wenn man bestehende Projektierungen nach IEC61131-3 nun formell in dieses Muster
umsetzt, dann entspricht ein AND mit NOT ENO-Input im IEC61131-3 einem AND mit Event-Eingang aus ENON in IEC61449. Gleichermaßen ist ein AND mit ENO-Input ohne NOT ggf. parallelgeschaltet zu der weiteren EN-Verarbeitung in IEC61131-3 adäquat einem AND mit Event-Eingang aus ENO in IEC61149. Damit lassen sich nach diesem Pattern beide Standards anpassen bzw. es sind formal IEC61131-3-Projektierungen
ggf. automatisch an IEC61449 upgrade-bar.
Etwas komplizierter wird es, wenn es mehrere ENO->NOT-Booleanverknüpfungen in einer IEC61131-3-Projektierung gibt. diese werden alle nacheinander abgearbeitet, weil die entsprechenden
ENO == false sind. In IEC61449 muss dazu dann eine Eventkette aus den ENON gebaut werden, die alle Boolean-Verwendungen trifft, mit Oderung der Event-Inputs der hinteren Logikbausteine. Das ist formell
aber immer noch ausführbar. (?) Das obige Bild zeigt einen Ansatz, der aber ggf. nicht so formal umsetzbar ist. Die Umsetzbarkeit
wäre gegeben, wenn ein Event auch als Boolean-Wert verarbeitbar wäre. Es müsste dann aber die Boolean-Verarbeitung auch getriggert
werden, wenn das Event nicht kommt, da dann der Zustand false ausgewertet wird. Möglich: Dafür dann ENON als Trigger verwenden. Die gezeigten E_RS-Fblocks scheinen der geeignete Ansatz dafür zu sein. (?)
Die Frage in diesem Rahmen ist zu stellen: Wie sieht es mit der Codegenerierung aus für den schnellen ns-Bereich ohne Eventqueue,
da die Funktionalität auch in diesem Fall nicht einer Eventqueue bedarf:
Eine Überlegung wäre, mit dem ENON eine if-Anweisung zu generieren, die zum Abbruch der Anweisungsfolge führt. Dieses if ist nur nach solchen FBlock notwendig, die dieses Verhalten zeigen.
Man könnte auch die Aussage 'event ENO gesetzt' für die Codegenerierung auf einen boolean-Returnwert setzen, diejenige Routine ruft also return true bei ENO gesetzt auf, sonst return false Damit kann für die betreffenden FBlock die zugehörige Anweisung (in diesem Fall C-Funktionsaufruf) im if stehen:
Wenn in einem längeren FBlock-Plan, der nacheinander bsp. 20 bis 100 FBlocks ruft, 3..10 solche dabei sind, die ein ENO im
Fehlerfall nicht erzeugen, dann entsteht im generiertem Code eine Schachtelung
die mit 20 Einrückungen an der Grenze der Überschaubarkeit liegt.
Ein anderer allgemeinerer Ansatz für diesen Fall sähe wie folgt aus:
Das ENO wird unbeachtet der Tatsache, dass es im Fehlerfall nicht kommt, nur als Abarbeitungsreihenfolge benutzt.
Wenn im FBlock ein Fehlerfall auftritt, dann soll der FBlock innen ein THROW erzeugen. Das kann auf ein C++-throw ohne extra Daten für ein einfaches catch(...) verwendet werden. Steht nur ein C-Compiler zur Verfügung, der aber longjmp unterstützt, dann funktioniert dies auch für THROW und CATCH, siehe emC:ExceptionHandling.
Die Abarbeitungsfolge ist in C(++) dann wie folgt zu generieren:
Das hat im Erfolgsfall für die Rechenzeit und Ziel-Sekundärquellcode den Vorteil dass keine if-Kette auftritt, also auch keine Rechenzeit für if-Abfrage, auch wenn diese kurz ist. Für den selteneren Nicht-Fehlerfall, der wegen Wegfall der Folgeverarbeitung sowieso mehr
Rechenzeitreserven hat, kommt die etwas längere throw->catch-Abarbeitung zum tragen. Die if-Abfrage des Fehlerfalls selbst muss algorithmisch sowieso vorhanden sein. Damit ist der Normalfall ohne Rechenzeitverlust
generierbar.
Bei der THROW-Variante wird aber der ENON-Zweig nicht richtig dargestellt wenn es mehr als eine ENON-Kette gibt. Es braucht dann ebenfalls geschachtelte TRY{...} die ebenfalss einen Aufwand darstellen.
Es tendiert damit eher zu der If-Variante.
7.4.3 Alle anderen Event-Behandlungen laufen über die Eventqueue
Topic:.FBG_UML_norm.ev.ev..
Last changed: 2019-04-16
bzw. über das Senden des Events an ein anderes Gerät und Eintragen in die dortige Queue. Die Versorgung der Statemachines
sollte ebenfalls nur aus der Eventqueue erfolgen, wie es für Statemachines auch in anderen Implementierungsplattformen üblich
ist.
Der unterstellte Anwendungsfall ist, dass ein Gerät extrem schnelle Abarbeitungen grafisch mit FBlock formuliert ohne Statemachine
mit den beiden Strategien der oberen Kapitel ausführt, also auch die Variante der Fehlerbehandlung. Beides läuft ohne Eventqueue.
Statemachines werden dagegen typisch in langsameren Abtastzeiten eingesetzt, da sie meist mit Kommunkation verbunden sind
und dann sowieso nie im kleinen µs-Bereich laufen.
Die Eventqueue braucht bei entsprechend schnellen Prozessoren auch nur wenige Nanosekunden. Wenn die Eventqueue aber für alle
schnellen FBlocks drankommen muss, dann multipliziert sich deren ns. Das wäre zu verhindern.
7.5 Einheitliche Herangehensweise
Topic:.FBG_UML_norm.ev.common.
Last changed: 2019-04-10
Es stellt sich die Frage, ob und wie diese verschienenen Herangehensweisen vereinbart werden können. Will man eine Einheitlichkeit der Grafischen Programmierung bei unterschiedlichen Tools, dann ist eine Vereinheitlichung
geboten und durch Style-Guides passend zu den einzelnen Tools herzustellen.
Geht man vom größten standardisierten Ansatz aus, dann wäre das die IEC61449.
Die direkte Eventverbindung im selben Gerät ist die einfache Abarbeitungsreihenfolgevorgabe.
Simulink: Wenn die Datenverbindungen insgesamt passen und es eine deutlich sichtbare Datenverbindung vom Voränger zum Nachfolge-FBlock
gibt, dann ist nur noch ein Styleguide notwendig, um zu regeln, dass dies das oberste Pin sein soll.
FBD nach IEC61131: Das wäre die ENO-EN-Verbindung, wobei der boolean-Steuergehalt (die Fehlermeldung, die Freigabe) auch im Simulink mit einer boolean-Datenverbindung
darstellbar wäre. Im IEC61449 ist die Fehleranzeige/Freigabe im Event verankerbar (? zu klären).
Quelltextdarstellung in FBCL: Die einfache Eventverbindung nur als Abarbeitungsreihenfolge braucht nicht extra dargestellt
werden. Sie ist immanent. Ein Fehleraustritt wird mit einem throw abgebildet, wobei die damit nicht ausgeführten Anweisungen genau den Verbindungen der folgenden ENO-EN-Kette entsprechen müssen. Wie sich dies abbilden lässt, ist noch zu klären. Jedenfalls braucht es eine solche Abbildung,
da sonst nicht nur die Textdarstellung sondern auch die Codegenerierung unnötig komplex wird und der Target-Code langsamer
wird.
8 Vorzüge oder Notwendigkeit einer textuelle Repräsentation der funktionalen Inhalte der FBlock-Datenfluss-Grafik
Topic:.FBG_UML_norm.fntxt.
Last changed: 2019-04-30
Die Parallelität von Text und Grafik ist in verschiedenen Grafikprogrammierumgebungen immer wieder gelebt worden. Letzlich
werden die Grafikinhalte in Dateien zumeist in textueller Form gespeichert. Man kann, oft als Workarround oder auch 'Geheimtipp',
in diesen Texten suchen und ändern. Es muss aber eine entsprechende Roundtrip-Funktionalität mit Syntaxcheck geben.
8.1 Textuelle Repräsentation nur der funktionalen Inhalte
Topic:.FBG_UML_norm.fntxt.onlyFn.
Last changed: 2019-04-30
Laut Überschrift des Hauptkapitels geht es nur um die textuelle Repräsentation des eigentlichen Funktionsumfanges. Wichtig,
aber nicht hier betrachtet kann auch eine textuelle Repräsentation des Grafikinhaltes, des Repositories etc. sein. Deshalb
wird im weiteren von der funktionalen textuellen Repräsentation geredet.
Das rechtsstehende Bild zeigt die Einordnung einer textuellen Function Block Connection Language (FBCL). Diese soll geeignet aus verschiedenen Tools der Grafischen Programmierung (... und Simulation) generiert werden. Die FBGL
enthält nur die funktionalen Aspekte, keine Grafikinformationen. Eine Versionierung kann daher unabhängig von dokumentatischen
grafischen Feinarbeiten Auskunft darüber geben, ob es funktionale Änderungen gegeben hat und welche.
Die Zielsystem-Codegenerierung erfolgt aus der FBGL. Aufgrund der Versionierung und textueller Repräsentation ist damit genau
klar, was der Funktionsumfang des Zielsystems ist. Bei der direkten Generierung aus der Grafik kann eine übersehene Änderung
einer Leitung schon Unklarheiten erzeugen.
Die Zielsystem-Codegenerierung über die FBCL ist damit auch unabhängig vom Grafiktool. Sind besondere Anforderungen vorhanden
(Rechenzeit, Parallelbearbeitung im Mulitcore nur als Beispiel), dann können diese als Speziallösung grafiktoolunabhängig
einmalig erstellt werden und passen für alle Grafiktools.
Die wesentliche Aussage für diese Herangehensweise ist: Die funktionale Präsentation von FBlock-Grafiken ist eigentlich immer
gleich, toolunabhängig. Schwächer ausgedrückt: Es gibt sehr viele Gemeinsamkeiten und eine deutliche Schnittmenge. Speziallösungen
eines Tools können ggf. damit nicht genutzt werden, wobei die Triggered Subsystems von Simulink noch nicht als Speziallösung angesehen werden sollten.
Es gibt einige Vorteile der funktionalen textuellen Repräsentation, die für Versionspflege, agile Tests und Dokumentation
eigentlich essentiell sind:
Die funktionale textuelle Repräsentation sollte den Funktionsumfang vollständig darstellen. Grafikpositionen, Info über aufgeklappte
Scopes, Zoom-Einstellungen und dergleichen dürfen dagegen dort nicht enthalten sein. Dann ist mit dem Versionsvergleich der
textuellen Repräsentation eindeutig feststellbar, ob es funktionale Änderungen in der Grafikmodellierung gegeben hat, und
welche. Hat man beispelsweise im Modell deshalb geändert, nur weil es aufgeklappt und mit anderem Zoom wieder zugeklappt und
gespeichert wurde, dann sind die Grafikfiles teils bereits geändert. Wenn man Ergänzungen für Tests anbringt, oder auch nur
aus dokumentatischen Gründen schönt, dabei aber die zielsystemspezifischen Module eigentlich oder vermeintlich nicht ändert,
dann ist dies in den Grafikfiles kaum eindeutig feststellbar. Man muss sehr genau analysieren mit vielleicht vorhandenen grafischen
Diff-Tools. Die funktionale textuelle Repräsentation nur der funktionalen Aspekte sollte aber in diesen Fällen textuell per
Diff-View für die betreffenden Module unverändert sein.
Günstig ist, wenn die Codegenerierung ausschließlich und direkt aus der von der Grafik abgeleiteten funktionalen textuellen
Repräsentation der funktionalen Inhalte ausgeführt wird. Dann ist die Aussage besser ableitbar: „Keine Änderungen der Funktion,
keine neuer Test und Auslieferung notwendig - trotz Änderungen aus den oben genannten Gründen im Modell“ . Wenn man bedenkt,
dass ein neues Zusammenbinden des Zielsystems einschließlich der notwendigen Tests möglicherweise in einer Kundenanlage oft
einige 10000 € kostet, dann ist dies sehr essentiell. Heutzutage wird oft auf die Verbesserung der Grafik (für Doku) im nachhinein
verzichtet, Tests am Modell werden ausgeführt aber man ist auf die mündliche Aussage der Entwickler angewiesen, dass dies
am gleichen Stand der Funktionalität geschehen sei. Für die Langzeitarchivierung wird dann der 'alte' Stand eingecheckt werden,
ohne dokumentarische und Test-Verbesserungen, weil eben von diesem Stand aus seinerzeit die Codegenerierung erfolge.
Versionsmanagement, Versionsvergleich und -merge auf Textebene gelingt oft besser. („Was wurde denn genau geändert ?“)
Die Suche nach Variablen, Blocknamen, oder auch nur spezifischen numerischen Werten gestaltet sich wesentlich einfacher (Textsuche
in mehreren Files), insbesondere dann wenn bei der Suche zunächst nicht genau bekannt ist, was denn genau gesucht werden soll.
Man kann an wagen Suchergebnissen aufgrund der Umgebungsstruktur abschätzen ob man richtig ist und die Erinnerung aktivieren.
Dies ist eine bekannte Vorgehensweise in der textuellen Programmierung, die in der Grafik oft so nicht unterstützt wird.
Günstig für diesen Fall ist es, wenn die Trefferstelle im Text auch in der Grafik angezeigt wird (über Rückverbindung vom
Text in die Grafik).
Suchen und Ersetzen eines eindeutigen Namens an mehreren Stellen in einem großen Modell ist einfach möglich. Text-Tools unterstützen
dies häufig besser als grafische umfassende Modelle.
8.2 Codegenerierung für das Zielsystem aus der funktionalen textuellen Repräsentation
Topic:.FBG_UML_norm.fntxt.cgen.
Die Codegenerierung selbst ist ein reiner Algorithmus, nicht schwieriger, sondern einfacher als aus dem Modell, da textuell
fassbar aus vorsortierten Anweisungen möglich.
Für den Hardwarehersteller eines speziellen Zielsystems kann diese Herangehensweise günstiger sein als das Angebot eines spezifischen
Komplett-Engineering-Tools, denn er muss aus der wohl- und einfach definierten Syntax nur für die spezifische Zielcode-Generierung
garantieren. Der Zielcode kann C(++) für Embedded sein, aber auch eine Automatisierungsgeräte-Ablaufsprache, Java-Code etwa
für Realtime-Java oder anderes.
Bei größeren Anlagen kann schonmal alte und neue Hardware oder Hardware verschieder Hersteller zusammenkommen. Das ist heutzutage
teilweise sogar kompatibel oder anpassbar. Für das Engineering beim Anwender ist die Beherrschung des jeweils spezifischen
Tools für jede Hardwareplattform aber eine Zumutung. Die mehrfachen Lizenzkosten sind bezahlbar. Aber die Mitarbeiter sind
oft auf ein bestimmtes Tool orientiert, es entstehen dann beim weniger bekannten Tool eher Fehler, Bearbeiter sind nicht austauschbar.
Es ist also ein Segen, wenn das Softwareengineering beim bekannten Tool bleiben darf und die Spezifika der Hardware nur die
entsprechende Batch-Toolchain benötigt.
Dies ist neben dem verbesserten Versionsmanagement der wesentliche Neuwert der funktionalen textuellen Repräsentation parallel
zur Grafik.
8.3 Roundtrip oder ''Revers engineering'' aus der funktionalen textuellen Repräsentation
Topic:.FBG_UML_norm.fntxt.rev.
Last changed: 2019-03
Wenn die Grafik ihre Positionen selbst ermittelt, wie es in den bekannten FUP-Darstellungen (Simatic) der Fall ist, dann sollte
eine Rücktransformation aus der Textrepräsentation eindeutig möglich sein.
Für Grafiken mit freier Positionierbarkeit muss folgendes gelten:
Für die geänderte Funktionalität im Text muss die Textrepräsentationen der originalen Funktionalität mit dem zugehörigem Grafikfile
vorliegen.
Dann kann über Vergleich der Grafikinformationen mit dem original generiertem Textfile und Differenzbildung der Textfiles
vom Grafiktool automatisch erkannt werden, was im Grafikfile geändert werden muss. Im Beispiel Simulink wird im slx-File die
Grafik als XML gespeichert, mit wohldefinierter und nachvollziehbarer Struktur. Über diesen Weg gelingt diese Zuordnung.
Wenn der Textfile zu stark geändert wurde, dann kann diese Rücktransformation, genannt Roundtrip im UML-Jargon, nicht mehr
ausgeführt werden, weil die Zuordnung nicht gelingt. Möglicherweise muss man in der Grafik zunächst manuell einen Zwischenstand
erzeugen. Bei Umbenennungen kann eine Zuordnung aus sich heraus scheitern. Führt man die Umbenennung in der Grafik manuell
durch, dann könnte die Zuordnung weiterer Details danach möglich sein. Diese Herangehensweise entspricht auch dem Roundtrip
in der UML.
Man kann jedenfalls auch manuell in der Grafik nachführen und den dann generierten funktionalen Textfile mit dem manuell geänderten
Textfile jeweils vergleichen. Das mag zwar als arbeitsaufwändig erscheinen. Wenn aber in einer Inbetriebsetzung ad hoc im
Textfile nachgebessert wurde, auch weil dies von der Toolchain her einfacher ist, dann ist die Nachbearbeitung im Entwicklungsbüro
nicht viel aufwändiger als die länger dauernde Vorbereitung für die Inbetriebsetzung. Wichtig ist, dass das Resultat, das
auf Anlage wirksam eingesetzt ist (am funktionalem Textfile erkennbar) im nachhinein genau über die Grafik erzeugt wird. Das
sollte immer möglich sein.
Das Roundtrip muss vom Grafiktool originär unterstützt werden. Die hier vorgestellte Arbeitsweise dürfte kundenfreundlich
sein. Also muss ein Kunde diese Unterstützung vom Grafiktool seiner Wahl auch einfordern. Die Toolhersteller sind häufig eher
geneigt, ihre Speziallösung zur protegieren.
9 Erarbeitung der Syntax der funktionalen textuellen Repräsentation von FBlock-Diagrammen
Topic:.FBG_UML_norm.syntaxText.
Last changed: 2019-04-15
Im Kapitel Chapter: 5 Vergleich der Funktionsblockdarstellung in Simulink und IEC61449 am Beispiel wurde gezeigt, dass auch die FBlock-Darstellung nach der IEC61449 in die Reihe der FBlock-Darstellungen, wie sie beispielsweise
von Simulink oder Modelica präsentiert wird, gehört. Die IEC61449 ist eine Norm. Andere Darstellungen sind herstellerspezifisch
und nicht genormt. Normen haben Vorteile, letzlich auch für die Sicherheit. Das Verhalten nach Norm kann geprüft werden. Ohne
Norm muss zunächst das Verhalten selbst toolspezifisch definiert und validiert werden.
Daher ist es angemessen, zunächst in der Norm IEC61449 oder der umfassenderen Basis IEC61131 zu bedienen. Letzrere definiert
Structure Text (ST) als textuelle Programmiersprache. ST ist innerhalb der FBlocks auch nach IEC61449 anwendbar. Die IEC61449 definiert
zusätzlich eine erweiterte ST-Syntax um Inhalten von Composite FBlocks (FBlock, der als Submodul FBlocks enthält) oder das
Gesamtsystem textuell darzustellen.
9.1 ST-Erweiterung für Composite Blocks in IEC61449
Die letztgenannte Darstellung: Inhalte von Composite FBlock (also Submodule aus FBlocks) mit erweiterter ST in IEC61449 sollte
vorderhand als die gesuchte betrachtet werden.
Ein Compoisite FBlock, also ein Submodul aus FBlocks, wird in IEC61449 textuell wie folgt präsentiert:
FUNCTION_BLOCK name (* Comment *)
EVENT_INPUT
.... (Interface des Blocks)
VAR_OUTPUT
....
FBS
name : type; (* comment *)
name2: type2(con := initialvalue, ....);
EVENT_CONNECTIONS
evX TO block.ev
.....
DATA_CONNECTIONS
dataX TO block.data
Ein System hat etwas andere Kopfdaten, jedoch den gleichen Aufbau der Benennung der internen FBlocks und deren Verbindungen.
Jedoch ist die Darstellung eher topologisch: Es wird der Inhalt der Grafik selbst repräsentiert. Die enthaltenen FBlocks werden
benannt. Die Verbindungen werden benannt.
Soll diese Darstellung allgemeingültig verwendet werden, dann ist festzustellen, dass beispielsweise die EVENT_CONNECTIONS so nicht auf Simulink oder Modelica zutrifft. Eine vergleichbare Funktion der Abarbeitungssteuerung ist in Simulink damit
gegeben, dass den Ports Abtastzeiten zugeordnet sind. Die Datenverbindung der Ports der Abtastzeit ersetzt also die Eventverbindung.
Sachlich ist damit der gleiche Zusammenhang gegeben, nur die grafische Darstellung, mithin auch diese Textrepräsentation ist
eine andere.
Der funktionale Überblick, wie er für eine funktionale textuelle Repräsentation günstig ist, fehlt.
Der folgende Abschnitt führt diesbezüglich zu einer Grundsatzüberlegung:
9.2 Anweisungsorientierte Darstellung
Topic:.FBG_UML_norm.syntaxText.stments.
Last changed: 2019-04-17
Die grundlegenden Programmiersprachen C(++), Java, auch Python sind anweisungsorientiert, bestehen aus hintereinander auszuführenden
Statements. Die Anweisungsorientierung ist nicht die einzige Präsentationsform höherer Programmiersprachen, sie ist nur gewöhnlich
verbreitet. Die im Vorabschnitt gezeigte IEC61449 für Composite Blocks und Systems ist topologisch. Eine dritte Form wäre
etwa eine regelbasierende Notation. Modelica benutzt die Equations, Notation in Gleichungen, die physikalische Zusammenhänge darstellen. Es ist also nicht vorauszusetzen, dass eine textuelle
Notationsform anweisungsorientiert zu sein hat, nur weil C(++), Java und co das sind.
Jedoch: Die Anweisungsorientierung ist die Grundlage der Implementierung. Auf Maschinenniveau arbeitet jeder Prozessor Anweisungen,
die Maschinenbefehle, ab. Daher ist C als maschinennahe Programmiersprache zweckmäßig anweisungsorientiert.
Soll die Funktionale Textrepräsentation einfach für die Codegenerierung zu verwenden sein, dann liegt die anweisungsorientierte
Form näher.
Auch für das Verständnis der Funktion ist eine anweisungsorientierte Form günstig. Das liegt zwar möglicherweise an der Gewöhnung
der Programmierer und des Umfeldes. Man denkt schon seit den Anfangszeiten der Rechentechnik anweisungsorientiert. Die Funktionale
Textrepräsentation soll aber tatsächlich die Nähe zur Implementierung haben, auch im Verständnis.
Daher erscheint die nichttopologische, anweisungsorientierte Schreibweise als besser geeignet.
9.3 IEC61449 für einen Basis-FBlock, dessen Inhalt in ST programmiert ist
Topic:.FBG_UML_norm.syntaxText.IEC61449FbBase.
Last changed: 2019-04-18
Die Frage stellt sich, wie sind Events und Abtastzeiten anweisungsorientiert zu formulieren. Klassich in C(++), Java & co
sind Abtastzeiten als verschiedene Routinen zu schreiben. Jede für sich ist anweisungsorientiert. Die Zuordnung der Routinen
zu Events und Abtastzeiten ist aus Sicht der Routine selbst ungeregelt, sie ergibt sich erst mit dem Aufruf. Selbiges gilt
für Eventbehandlungs-Routinen.
Schaut man auf die Syntax einens Basis-FBlock nach IEC61449, dann sind dort die Zuordnung der Anweisungen zu Events, Abtastzeiten
und States geregelt:
FUNCTION_BLOCK name (* Comment *)
EVENT_INPUT
name WITH inputvariables, ...; (* comment *)
....
EC_STATES
statename: entryRoutine -> outputEvent
....
ALGORITM name IN ST
statements of ST language
....
ALGORITM name IN ST
statements of ST language
....
END...
Es sind jeweils ALGORITHM-Abteilungen vorhanden, die entweder den State-Entries oder den Events direkt zugeordnet sind, wenn keine Statemachine zum
FBlock gehört. Die Events selbst haben Boolean-Character: Sie treten entweder auf, oder nicht. Die Daten zu den Events sind
an den Dateneingängen plaziert, die Zuordnung der Daten zu Events ist definiert, wobei die selben Daten mehrfach zu Events
zuordenbar sind.
Nun entspricht beispielsweise aus Simulink die Zuordnung der Abtastzeiten (über entsprechende Input-Datenports) den einfachen
Events. Ein Event INIT in IEC61449 entspricht typisch der Init-Abtastzeit in Simulink, RUN1 als Eventname entspricht für den einfachen Nicht-Statemachinen-Fall einer bestimmten Abtastzeit in Simulink, weil RUN1 mit dem entsprechenden Out-Event CNF1 in einer Eventkette zwischen mehreren FBlocks liegt, also nacheinander aufgerufen wird, adäquat der Abarbeitungsreihenfolge
im Simulink. Im Modelica ist das in
algorithm
when (initial) then
.... statements for initalizing
end when;
when sample(0, Tstep) then
.... statements for this step time
geregelt. Hier ist die Zuordnung der Datenin- und outputs nicht explizit angegeben, aber es lässt sich analysieren, welche
Daten verwendet werden.
Das heißt, die Schreibweise in IEC61449 für die Zuordnung der Anweisungen zu Events und damit Abtastzeiten passt sowohl auf
Simulink als auch sogar ähnlich geschrieben auf Modelica. Sie lässt sich leicht in optimal abarbeitungsfähigen C-Code umsetzen,
da die Statements zugeordnet zu Events oder Abtastzeiten, oder auch Statemachine-Routinen, einfach in entsprechende C-Routinen
überführbar sind, deren Aufruf dann ebenfalls im Ablaufsystem organisiert werden kann.
Folglich scheint dies das geeignete Grundgerüst zu sein.
9.4 Definition der FBlocks in ST nach IEC61131-3 und IEC61149
Topic:.FBG_UML_norm.syntaxText.defFB.
Last changed: 2019-04-20
Sowohl in ST nach IEC61131-3 also auch in IEC61449 werden die enthaltenen FBlocks in etwa ähnlich definiert ggf. gemeinsam
mit Initialisierungswerten.
Die Definition wird hier für IEC61131 ausführlich aus dem Standard dargestellt:
Die Definition wird auf Seite 44 am Beipiel eines Temparaturregelkreises erläutert:
.
Die formelle Syntax findet sich auf Seite 151 ... 153 etwas verschachtelt, hier top-down sortiert und gekürzt für die Definition,
in EBNF (Enhanced Backus Naur Format von Prof. Niklaus Wirth):
Das gehört zu den Expressions, was letztlich für constant steht, und dann Operators.
9.5 Formelle Syntax anstatt in EBNF in ZBNF
Topic:.FBG_UML_norm.syntaxText.ZBNF.
Last changed: 2019-04-20
Die Definition anstelle in EBNF in ZBNF (Semantic Backus Naur Format) sieht etwas übersichtlicher aus. Der markant sichtbare
Unterschied ist: Syntaxkomponenten werden in <syntax> geschrieben, wogegen Klartext ohne Anführungszeichen erscheint. Ein Semantikbezeichner kann angegeben werden: <syntax?semantic> wobei der Semantikbezeichner beim Parsen zur Identifikation zum Abspeichern benutzt wird. Die Syntaxsteuerzeichen [|] {?} ::= <>. etwa die gleichen wie bei EBNF, werden direkt geschrieben. Wenn diese als Textinhalt benötigt werden, dann muss mit vorangestelltem
\ gearbeitet werden. Bestimmte Grundelemente sind direkt bezeichnet, beispielsweise <$?semantic> ist ein Identifier. Da eine ZBNF-Syntaxbeschreibung direkt als Script verwendet werden kann, wird sie insoweit auf Widerspruchsfreiheit
und Richtigkeit formell getestet. Das ZBNF-Format ist in ZBNF beschrieben.
Es entfällt das := vor der Argumentliste, ansonsten identisch.
9.6 Anlehnung an ST (IEC61131-3) für den Aufruf von FBlocks
Topic:.FBG_UML_norm.syntaxText.callFB.
Last changed: 2019-04-20
Wenn die topologisch orientierte Textform nach Chapter: 9.1 ST-Erweiterung für Composite Blocks in IEC61449 nicht verwendet werden soll, dann stellt sich erneut die Frage, wie die Einordnung der FBlocks in einen Composite FBlock
(Submodul) zu notieren ist. Immerhin kann nicht der FBlock selbst direkt als solcher aufgerufen werden, da er aus mehreren
Eventreaktionen oder Abtastzeit-Zuordnungen besteht.
In ST nach /IEC61131-3/ ist es möglich, einen FUNCTION BLOCK zu rufen. Der Standard enthält dazu nur folgenden Text (Zitat im Bild, Abschnitt 3.3.2.2. S. 133):
Die Tabelle auf S. 132 ist wie folgt als Zitat im Bild angegeben:
Auf Seite 161 wird in EBNF-Syntax folgendes dazu angegeben:
In IEC61449 findet sich eine adäquate Definition nicht, es gilt also für ST die IEC61131-3. Um auch bei Composite-Blocks
diese adäquate Form zu verwenden, sind einige Änderungen erforderlich:
Der Aufruf der FBlocks soll nicht ein beliebiger Teil der Expression sein, sondern genau ein einzelner Aufruf, der so für
einen FBlock in der Grafik steht.
Ein Returnwert ist möglich, siehe Diskussion Sonderfälle.
Zusätzlich gibt es noch eine wichtige Überlegung:
Die Abarbeitungsfolge von gerufenen FBlock steht wie im Basic-FBlock innerhalb der zugehörigen
Hinweis: Für die obige Darstellung ist die ZBNF-Syntax verwendet, liest sich evtl. gut.
Damit wird aber nicht der gesamte Block gerufen, sondern nur der Teil des Blocks, der für das entsprechend verdrahtete Event
zugehörig ist. Wenn der Block eine einfache Standard-Statemachine hat, wie sie in Chapter: 7.4.1 Event wirkt eigentlich nur als Abarbeitungsreihenfolge-Bestimmung oder Chapter: 7.4.3 Alle anderen Event-Behandlungen laufen über die Eventqueue gezeigt ist, bzw. wenn sich diese Statemachine-Darstellung bei der Darstellung aus einem anderen FBlock-Tool (Simulink, Modelica)
sich so ergeben würde, ohne so explizit angegeben zu sein, dann ist ein Input-Event direkt der zuehörigen Operation zugeordnet,
genauso wie in den gezeigten Kapiteln dem Output-Event. Dann kann die Inputevent-Bezeichnung in der Schnittstelle auch für
die Bezeichnung der Operation benutzt werden.
Wenn der FBlock eine komplexe Statemachine enthält, dann ist dies genauso, nur die Codegenerierung ist komplexer.
Man muss folglich beim Aufruf noch das Inputevent angeben. Es wird dazu folgende Schreibweise vorgeschlagen (ZBNF-Syntax):
Es tritt das $ als Trennzeichnen zwischen instancIdent$event auf. Hinweis: In der ZBNF-Schreibweise haben die <$? hier die Bedeutung, ein identifier zu meinen, das kann in diesem Fall etwas zuviel $ sein, ist aber eindeutig.
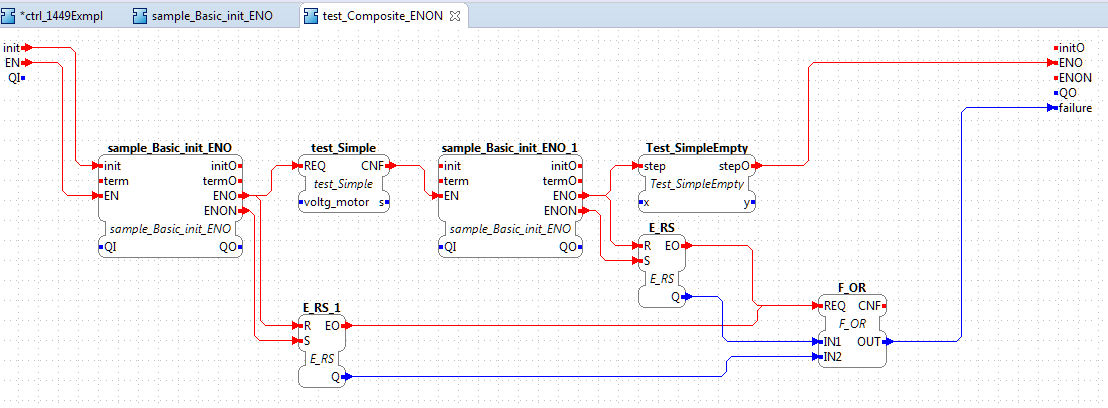
FUNCTION BLOCK ctrl_1449Exmpl
EVENT_INPUT
init WITH par; (*Simulink: init-Sampletime*)
step WITH w,x,test; (*for the step-Sampletime*)
END_EVENT
EVENT_OUTPUT
initO <-init; (*For execution queue*)
stepO WITH yctrl, xSim <-step;
stepSimOk WITH xSim <-step;
END_EVENT
VAR_INPUT
par: UDINT; (* Handle for parameter *)
w: REAL; (* set value *)
x: REAL; (* current value *)
test: BOOL; (*switch to test with internal environment*)
END_VAR
VAR_OUTPUT
yctrl: REAL; (*actuator value*)
xSim: REAL; (*simulated x-value*)
END_VAR
VAR
F_SEL_1$OUT : REAL; (*automatic output of F_SEL1*)
F_SUB_1$OUT : REAL;
END_VAR
FBS
F_SEL, F_SEL_1: FSEL;
F_SUB, FSUB1: F_SUB;
F_ADD: F_ADD;
ctrl1: PIDctrl;
envionmnSim: Mod:Environment;
END_FBS
ALGORITHM init IN STx
ctlr1$init(par:=par);
environmSim();
->initO;
END_ALGORITM
ALGORITHM step IN STx
ctrl1$step( w_x:=
F_SUB(IN1:= w, IN2:=
F_SEL(G:=test, IN0:=y, IN1:=environmSim:=s)
) );
yctrl := ctrl1.y;
->stepO;
F_SEL1$y := F_SEl1(G:= test, IN0:= x, IN1:=0);
environmSim$step(voltg_motor:=
F_ADD(IN1:= ctrl.y, IN2:= F_SUB_1$OUT)
);
F_SUB_1$OUT:= F_SUB_1(IN1:= environmSim.s, IN2:= F_SEL_1$OUT);
sSim := environmentSim.s;
->stepSimOk;
END_ALGORITM
END_FUNCTION BLOCK
Diese Schreibeweise wurde formell manuell aus der Grafik geschrieben und ist für das Beispiel intuitiv eine mögliche Schreibweise.
Es ergeben sich dabei folgende Fragen/Problemkreise:
1) Ist die FBCL-Quelle manuell verstehbar? Das sollte so sein, damit bei DiffView-Anzeigen erkennbar ist, was funktionell
geändert ist.
2) Wenn eine Kleinigkeit im Modell geändert wurde, dann soll die FBCL-Erscheinung auch nur in dieser Kleinigkeit geändert
erscheinen, wichtig für DiffView. Wird eine Abarbeitungsreihenfolge geändert, dann ist die Zeilenreihenfolge geändert, das
ist ok.
3) Grundfunktionen haben keine Daten. Sie sollten auch in der FBCL-Darstellung nicht etwa aus formalen Gründen Daten bekommen,
denn das würde auch die Codegenerierung für Target erschweren. Typische Grundfunktionen sind Arithmetik und Boolean-Verknüpfungen.
Wenn diese Grundfunktionen genau einen Ausgangswert haben, dann ist das der Returnwert der FUNCTION.
4) Dieser Returnwert wird entweder direkt für die Zuweisung zum Folgeblock-Input benutzt. Dann entsteht die Schachtelung wie
für ctrl1$step(...). Das ist immer möglich, wenn der Ausgang nur ausschließlich für den direkt in der Eventverdrahtung folgenden Block benutzt
wird. Das ist aber ein typischer Fall.
5) Oder der Returnwert wird in einer automatisch erzeugten Zwischenvariablen gespeichert, die in der Grafik quasi der Verbindung
(line) darstellt. Das ist dann notwendig, wenn entweder der Ausgang nicht im unmittelbar folgenden Block verarbeitet wird,
oder an mehreren Eingängen hängt.
6) Auch komplexe FBlocks können ohne Daten sein. Das sind insbesondere die Operation-FBlock nach der ObjectOrientierung im
FBlock-Modell. Haben diese nur einen Ausgang, dann gilt gleiches wie 3) bis 5). Haben diese mehr als einen Ausgang, dann wird
ein Hauptausgang definiert (dies kann immer der erste im Grafischen Modell sein), der als return verwendet wird. Alle anderen
Ausgänge sind mit
FBlockFn(..., OUT=> FBLockFn$OUT, ...)
zu schreiben. Der Ausgangszuweisungsoperator ist in IEC61131-3 für ST definiert, siehe Syntax subprogram_control_statement.
In diesem Beispiel wird das Event stepO erzeugt bereits wenn der ctrl1 abgearbeitet wurde. Sachlich kann das wichtig sein, denn die Weiterverarbeitung in environmSim kann auf einen Fehler hinauslaufen, so dass stepSimOk nicht kommt, da environmentSim$stepO nicht erzeugt wurde. Die Software kann mit diesem Fehler dennoch aktiv regeln, nur die
Kontroll-Strecke liefert keine Ergebnisse.
Beim Aufruf dieses Moduls bedeutet das, dass es abfragbar zwei Output-Events gibt. Diese müssen, wenn sie nur die Rechenzeitreihenfolge
bestimmen und nach Chapter: 7.4.3 Alle anderen Event-Behandlungen laufen über die Eventqueue aber zusätzlich als Fortsetzungsbedingung, als boolean-Wert verfügbar sein.
7) Da keine Statemachine untergebracht werden soll (das grafiksche Modell hat auch keine), muss das Event also bedingt in
der ALGORITHM-Folge gesetzt werden. Das ist mit der Schreibweise
->outEvent
hier formuliert. Die Frage nach dem Setzen eines Out-Event im Algorithmus wurde auch in dem eben verlinkten Kaptiel angesprochen.
Es wäre eine Überlegung wert, solche Dinge in einer Fortschreibung des IEC61449 zu berücksichtigen. Events würden somit grundsätzlich
nicht nur aus Statemachine, sondern auch aus if-Bedingungen resultieren können.
Die folgenden Überlegungen sind notiert nachdem die Parallelabarbeitung im Folgekapitel als beachtenswert beschrieben wurde.
Ebenso die Optimierung des Modells durch Weglassen nicht benötigter Aufrufe.
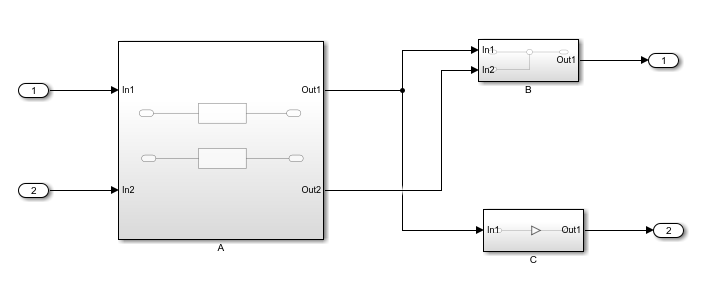
Das obige Bild zeigt ein Submodul in Simulink mit einigen Verküpfungen. Farblich sind Teile markiert, die unabhängig zu rechnen
sind:
a() wird berechnet, sobald x1 und x2 besetzt sind (deren Events gekommen sind)
b() wird bereits berechnet, wenn x2 allein gekommen ist. a) und b) kann parallel laufen
c() wird berechnet sobald x2 gekommen ist. Es wird aber als Folge d) angestoßen.
d() wird berechnet nachdem c) berechnet wurde. Das ist eine update()-Routine für die Speichervariable q im Simulink mit dem
Unit delay 1/z ausgedrückt.
Die Unterteilung in diese Operationen ist aus Simulink-Codegeneriergründen sinnvoll, weil:
Wird nur ya1 abgegriffen, dann wird auch nur a() berechnet. Adäquat für b(). Die aufwändige Operation für d() entfällt dann auch.
Wird yc abgegriffen, dann wird c() berechnet, und danach mit d() das update der Speichervariable ausgeführt.
Dies bewirkt die Simulink-Codegenerierung aufgrund Wegfalls nicht genutzter Signale.
Werden alternativ diese farbigen Operationen als eigenständige Operationen des FBlock realisiert, dann erfolgt etwa gleiches
Verhalten: Wird y1a benötigt, dann wird alles berechnet, was x1 und x2 versorgt, dann a(). Die Operationen c() und d() werden, wenn nicht benötigt, auch nicht aufgerufen.
Das obige Bild zeigt ein Submodul in Simulink mit einigen Verküpfungen. Farblich sind Teile markiert, die unabhängig zu rechnen
sind:
a1() wird berechnet, sobald x1 und x2 besetzt sind (deren Events gekommen sind). Für die Optimierung zur Laufzeit wird es
aber nur berechnet, wenn ya1 benutzt wird (das Outpin angeschlossen ist).
e) ist für a1() notwendig, wird berechnet wenn x1 und x2 anstehen und muss vor a1() berechnet sein.
a2() ist ad#quat a1(). Es braucht nicht berechnet werden, wenn ya2 unbenutzt ist. Aber a2() kann parallel zu a1() berechnet werden.
b() wird berechnet, wenn x2, x2, x4 gekommen sind. Es kann parallel laufen. Die Ausgänge yb1 und yb2 sind zusammengefasst über den mux. Das ist eine Hilfskonstruktion, die bedeuten soll, dass yb1 und yb2 immer zusammen bereitgestellt werden, unabhängig ob einer der Ausgänge unbenutzt ist. Das ist hier nicht Ergebnis einer automatischen
Optimierung, sondern Ausdruckswille im Modell. Damit wird aber auch yb1 erst berechnet, wenn x3 und x4 anstehen, auch wenn sie hierfür nicht gebraucht werden!
c() wird berechnet sobald x2 gekommen ist. Es wird aber als Folge d) angestoßen.
d() wird berechnet nachdem c) berechnet wurde. Das ist eine update()-Routine für die Speichervariable q im Simulink mit dem Unit delay1/z ausgedrückt.
Hinweis: Das update() wird immer zuletzt gerechnet. Zu beachten ist, dass updates möglicherweise andere Speichervariable benötigen, deren update
also entweder erst danach gerechnet wird, oder die Speichervariablen werden dupliziert berechnet und im lezten Schritt gemeinsam
kopiert. Das ist wichtig, weil es sonst Fehlfunktionen wegen falscher Zuordnungen des zeitlichen Verlaufs von Werten gibt!
Die Unterteilung in diese Operationen ist aus Simulink-Codegeneriergründen sinnvoll, weil:
Wird nur ya1 abgegriffen, dann wird auch nur a1() berechnet. Adäquat für a2(), b() usw. Die aufwändige Operation für d() entfällt wenn c() nicht berechnet wird.
Wird yc abgegriffen, dann wird c() berechnet, und danach mit d() das update der Speichervariable ausgeführt.
Dies bewirkt die Simulink-Codegenerierung aufgrund Wegfalls nicht genutzter Signale.
Werden alternativ diese farbigen Operationen als eigenständige Operationen des FBlock realisiert, dann erfolgt etwa gleiches
Verhalten: Wird y1a benötigt, dann wird alles berechnet, was x1 und x2 versorgt, dann a(). Die Operationen c() und d() werden, wenn nicht benötigt, auch nicht aufgerufen.
Diese Betrachtung ist unabhängig von der Event-Verbindung nach IEC61449. Es sind zwei Dinge maßgeblich:
Weglassen von Operationen wenn diese nicht benötigt werden, wenn die Ausgänge nicht abgegriffen werden.
Paralleles Bearbeiten.
Für IEC61449 ergibt sich mit den Grundoperationen folgende Statemachine:
Die Zustandsnamen entsprechen etwa den Routinen, die on entry aufgerufen werden. Kommt x1 mit ev1 zuerst, passiert zunächst nichts. Erst mit ev2 werden b(), c() und a() und danach d() aufgerufen. Kommt x2 mit ev2 zuerst, dann kann sofort b() und c() ausgeführt werden, um dann auf ev1 zu warten.
Die Parallelität der Verarbeitung wird allerdings erst mit folgender in Rhapsody (UML) gezeichneter Statemachine deutlich:
Die Output-Events sind hier aus Platzgründen nicht eingezeichnet, kommen aber wie bei der 4diac-StM.
Beide Statemachines zeigen den Ablauf 'von vorn': Kommt ein Event, dann werden mit dem Stateeintritt die entsprechenden Teil-Operation
ausgeführt. Beide Event müssen kommen, sonst verharrt die StM im Wartestate und arbeitet nicht mehr.
Codegenerierung Aufrufe, StM rückwärts lesen:
Für die Codegenerierung kann die Statemachine quasi rückwärts interpretiert werden, und zwar von den ausgehenden Events aus:
Ist nur Ausgang yb benutzt, dann reicht das Auftreten von evb, damit der Aufruf von b() und das Input-Event ev2. ev1 ist unnötig, damit ist auch das Ausgangsevent des davor liegenden FBlocks unnötig und diese Codegenerierung entfällt ebenfalls.
Ist nur yc benutzt, dann braucht es das evd mit yc im 4diac verbunden. Es muss folglich d() aufgerufen werden (erzeugt das Event). Dazu ist aber ev1 mit x1 notwendig, das folglich als Vorbedingung gilt und vorher codegeneriert eingefügt werden muss. Davor im State, rückwärts zum
Start, liegt mit State c der Aufruf von c(). Dieser erzeugt kein eigenes Event und muss daher jedenfalls als Vorbedingung für State d generiert werden. Im UML-Statediagramm
erkennbar liegt State b mit eigenem evb parallel, wenn evb nicht benötigt wird, ist die Routine b() also auch nicht zu generieren. Damit aber c() arbeiten kann, braucht es ev2 mit x2 als Vorbedingung.
Am Beispiel untersucht und ausgeführt könnte diese Regelung immer gelten (TODO noch nachdenken). Folglich ist die Statemachinedarstellung
mit Events geeignet, auch für die Codegenerierung sowohl die Aufrufreihenfolge festzulegen als auch, on überhaupt aufgerufen
wird.
Allerdings ist für das Weglassen oder parallele Ausführen der Operationen eine Darstellung paralleler States notwendig.
10 Anforderungen für Optimierungsmöglichkeiten im generierten C-Code für fast runtime
Topic:.FBG_UML_norm.opt.
Last changed: 2019-04-27
Das hier gezeigte Herangehen ist in erster Linie für die Grafische Programmierung von Embedded Prozessoren gedacht, als Ablösung
der manuellen C-Programmierung. Im Embedded Bereich ist die Rechenzeit zumeist eine knapp bemessene Größe:
Entweder es werden kleine stromsparende Prozessoren eingesetzt mit geringer Taktfrequenz
Oder es ist in kurzer Abtastzeit umfangreich zu rechnen. Beispiel Regelung in elektrischen Netzwerken mit physikalischen Zeitkonstanten
im kleinen ms-Bereich. Auch mechanische Bewegungen, z.B. mit 3 m/s Stellgeschwindigkeit sind mit 3 mm/ms zu ungenau. Abtastzeiten
im Bereich um 50 µs erweisen sich als notwendig.
Folglich ist das unnötige Rechnen von Modellteilen, die etwa nur zum Test am PC designed worden sind, oder nur im konkreten
Fall unnötig sind, zu vermeiden. Die manuelle Herausnahme der Modellteile vor der Codegenerierung ist keine Lösung, da sie
Versionierung für nachfolgende Tests, Reusing für andere Aufgaben usw. erschwert. In C gibt es die Möglichkeit der bedingten Compilierung (#ifdef ...), für solche Fälle gern angewendet.
10.1 Simulink: flatten
Topic:.FBG_UML_norm.opt.flat.
Last changed: 2019-04-27
Simulink lässt bei der Codegenerierung Modellteile weg, wenn deren Ausgang nicht benutzt wird. Die Codegenerierung wird für
den konkreten Fall durchgeführt, die Nichtbenutzung kann allein schon durch einen manuellen Schalter organisiert werden, der
vor der Codegenerierung umgeschaltet wird. Damit dies über Modulgrenzen, insbesondere in Submodule hinein wirksam ist, löst
Simulink für die Codegenerierung Submodule auf zu einer durchgehenden Blockverdrahtung, wenn die Submodule nicht als atomic gekennzeichnet sind: flatten, prägnant als flachklopfen übersetzbar. Für den generierten Code hat das den Nachteil, dass die Submodule als solche nicht erkennbar sind und auch Identifier,
die im Modell bekannt sind, für die Namensbildung der Variablen im C-Code nicht genutzt werden.
Ein anderer Grund für das flatten in Simulink ist allerdings, dass numerische Schleifen, die sich nur scheinbar über ein Modul bilden, aufgelöst werden können:
Wenn das unterbrechende Unit delay sich in einem tieferen Submodul befindet. Hier gilt für atomic Subsystems, dass diese ein solches Construct eben nicht haben dürfen.
Das flatten in Simulink wird erfolgreich als Optimierungsschritt dargestellt, der so sonst nicht möglich wäre, ein handgeschriebener
Code wäre daher möglicherweise weniger optimal als ein generierter Code mit diesem Optimierungsschritt.
10.2 Aufteilung in Operations per FBlock
Topic:.FBG_UML_norm.opt.op.
Last changed: 2019-04-27
Die andere Möglichkeit, sowohl die Optimierung als auch das Erkennen von Unterbrechungsstellen bei numerischen Schleifen auszuführen,
ist die Zerlegung eines Submodules in einzelne Operationen, die die jeweils unmittelbar abhängigen FBlocks zusammenfassen
und jedenfalls an Unit delays gebrochen werden, auch an Verzweigungen von Signalen. Ist ein Ausgang unbenutzt, dann wird die Signalaufbereitung für diesen
Ausgang auch nicht aufgerufen, da diese Operation des Moduls nicht aufgerufen wird. Dabei wird aber nicht Speicherplatz für
den Maschinencode eingespart, sondern nur die Rechenzeit wegen dem Nicht-Aufruf. Jedoch ist der Speicherplatz eine weniger
wichtige Optimierungsgröße. Die Speicheroptimierung lässt sich im Nachhinen aber auch noch ausführen, da bekannt ist, welche
Routinen im umliegenden Code aufgerufen werden.
Wird beispielsweise eine Winkelaufbereitung neben den numerischen Winkelwert (sinnvoll als Integer in der Integerauflösung
auf -180..179.999 ° abgebildet) zusätzlich noch als komplexer Wert über sin und cos dargestellt, dann benötigt diese Berechnung
in einem schnellen Signalprozessor (TigerSHARC von Analog Devices) 100 ns. Wird der komplexe Winkel an mehreren Stellen gebildet
und vom umliegenden Design nicht genutzt, dann ist das eine relevante Rechenzeitvergeudung.
Wenn in einem Modul eigentlich nur auf den Ausgang eines tieferen Submoduls zugegriffen wird, dann wird mit dem flatten direkt zugegriffen. Ohne flatten steht mindestens diese Operation dazwischen. Wird in der C-Codegenerierung die Zugriffsfunktion aber als inline ausgeführt, dann wird im eigentlichen Maschinencode nun doch direkt, also zeitoptimal zugegriffen. Die Compiler für den C-Code
tuen einiges für die Optimierung.
Schlussfolgerung: Das flatten ist nicht notwendig, aber die Untergliederung eines Moduls in Operation ist angemessen.
Wenn nun ein Modul des Simulink in eine FBCL-Zwischensprache nach IEC71449 übersetzt wird, die keine Operation als solche
kennt, dann muss es einen adäquaten Mechanismus geben, der für die Codegenerierung diese Operations noch herauslösen kann.
Die Untergliederung in
ALGORITHM event ...
END_ALGORITHM
ist einen Untergliederung in Operation, die aber für ein Event, oder eine Abtastzeit bezogen ist.
Wenn eine Zuweisung auf eine Outputvariable, möglicherweise mit einer operation davor, als eine Anweisung erkannt wird:
outVar := fb1.y * fb2.y;
dann kann diese Zeile etwa für eine Codegenerierung in C als
umgesetzt werden. Der Zugriff auf das Outport eines FBlocks im Modell (nach IEC61449, Simulink etc) ruft also diese Routine
auf. Erfolgt der Zugriff mehrfach (Abzweig am Ausgang), dann wird die Routine nur beim ersten Zugriff aufgerufen, das Ergebnis
im rufenden Modul zwischengespeichert und wiederverwendet.
Folglich existiert eine Output-Variable nicht unbedingt im generierten Code als Datenzelle. Trifft das auch für den Sub-FBlock
fb1 zu, dann sieht der generierte Code an dieser Stelle wie folgt aus:
Ist get_y_Fb1(...) wiederum inline, dann führt der Compiler die geeignete Optimierung schon aus.
Überlegenswert ist nun, ob die eine Zuweisungszeile zur Outputvariablen ausreichend ist für diesen Optimierungsschritt, oder
ob extra Kennzeichnungen notwendig sind. Das rechtsstehende Bild ist aus einem Beispiel in dem die Zerlegung eines Submoduls
in Operation gezeigt wird.
Wenn man den Ausgang y1b abruft, dann über eine inline-getter-Routine. Diese führt die zugehörige Multiplikation (oder eine umfassendere Berechnung) erst aus. Zuvor muss aber die
Routine calc_y1a(..) gerufen werden, da der getter sonst auf nicht berechnete Zwischenwerte zugreift. Dazu gibt es in der Simulink_to_Java-Codegenerierung,
aus der dieses Beispiel stammt, eine Reihenfolgeangaben der Operationen des Submoduls.
Wenn im äußeren aufrufenden Modul nun diese beiden Operations im Ablauf bereits gerufen wurden, dann ist das get_y1a() direkt aufrufbar. Die Codegenerierung des äußeren Moduls muss dies berücksichtigen.
10.3 Parallele Abarbeitung
Topic:.FBG_UML_norm.opt.par.
Last changed: 2019-04-27
Leistungsfähigere Prozessoren im Embedded Bereich haben oft mehrere unabhängige Cores.
Eine Möglichkeit, diese Cores zu nutzen ist die manuelle Aufteilung von Hauptfunktionen auf diese Cores. Beispielsweise der
Interrupt für die schnelle Regelung läuft auf einem bestimmten Core allein. Ein anderer Core ist allen langsamen Abtastzeiten
vorbehalten, ein dritter Core ist für Kommunkation.
Wenn aber zukünftig es 16 Cores in Embedded Prozessoren gibt, dann sollte ein neuer Ansatz der Formulierung der grafischen
Programmierung diese Capabilities nicht vergessen. Die direkte C-Codegenerierung aus grafischen Modellen kann spezifisch auf
Multicore ausgelegt werden, da das Modell Parallelitäten und leicht erkennen lässt. Datenverbindungen sind direkt ablesbar.
Eine Zwischensprache FBCL muss diese Eigenschaft ebenfalls enthalten. Aus der reinen Statement-Notation sind Datenverbindungen
und damit Parallelität-Verhinderungen weniger gut erkennbar. Die grafisch unabhängig erkennbaren Modellteile aus der Zusammenschaltung
mehrerer FBlocks müssen sich in separaten Teilen innerhalb der ST-Statements wiederfinden.
Die Aufteilung in ALGORITHM für die Events in einem FBlock-Text nach IEC61449 ist für eine Parallelisierung verwendbar, wenn es keine Mutex-Probleme
gibt. Sicher ist hier die Abarbeitung eigentlich nur sequentiell, da dann Daten, die von einem anderen ALGORITHM bearbeitet worden sind, konsistent abgegriffen werden.
10.4 Mutex, Doppelpufferung und Konsistenz der Daten
Topic:.FBG_UML_norm.opt.mutex.
Last changed: 2019-04-27
Wenn in einem Thread (einem Core) es kein unterbrechendes Multithreading gibt sondern nur kooperatives, dann sind Dateninskonsistenzen
ausgeschlossen, es ist kein Datenzugriff als Mutex (mutial exclusion) notwendig. Ein einfaches System arbeitet mit untersetzten
Abtastzeiten in einem einzigen Thread oder direkt im Hardwareinterrupt. Diese Herangehensweise ist auch im Simulink bekannt
und verbreitet.
Aus Simadyn (Siemens, 1990..2000) ist bekannt, dass der Wechsel der Abtastzeiten mit relativ viel Aufwand verbunden ist, Es
wurde grundsätzlich Doppelpufferung eingesetzt. D.h. eine parallele Abarbeitung (es gab dort auch parallel auf einem gemeinsamen
Rückwandbus arbeitende Prozessoren) griff also immer auf einen anderen Datensatz zu. Faktisch braucht es aber nur wenige Daten
mit Konsistenz, beispielsweise zueinander in Beziehung stehende Messwerte. Die Frage, ob ein einzelner Sollwert aus der aktuellen
oder der vorigen Abtastzeit stammt, ist häufig unwesentlich. Besteht aber der Sollwert aus mehreren Komponenten (d und q bei
Transvektorregelung), dann sollten diese Werte schon konsistent sein.
Aus gewöhnlichen Multithread-Betriebssystemen sind die Mutex-Zugriffe bekannt. Diese führen dazu, dass der zugreifende Thread
kurz angehalten wird, damit ein unterbrochener Thread seinen Zugriff erst fertigstellt, führt also zu Threadwechsel. Dies
ist aber bei schnellen Abtastzeiten (50 µs) nicht erwünscht.
Folglich ist eine Doppelpufferung der Daten geeigneter.
Das Eventsystem der IEC61449 regelt die Reihenfolge der Bearbeitung und führt mit den Kommunikationswegen zwischen den Devices
zu der korrekten Verteilung der Daten. Es sollte hierbei ausreichende Strategien auch für die Multicore-Zukunft möglich sein.
Event wird empfangen
Start der lokalen Bearbeitung lockt einen Wechselpuffer-Zeiger. Es wird auf den nicht referenzierten Puffer gearbeitet.
Ende der Bearbeitung schalten den Wechselpufferzeiger auf die neu bearbeitete Daten.
Zusammenhang zwischen Ablauf (Event, Anweisungen) und den zugehörigen Daten muss klar sein. Diese Klarheit sollte der Schlüssel
zum Erfolg sein.
11 Textrepräsentation eines Moduls mit topologisch
Eine zweite Überlegung verschiebt die Aufwandszuordnung:
Wenn man davon ausgeht dass die FBCL als Bindeglied verschiedener Tools für die Funktionale Beschreibung und für die Zielsystem-Codegenerierung
taugen soll,
dann ist die Anzahl der zu unterstützenden Tools der Grafischen Programmierung nicht niedrig. Das System soll ja nicht nur
etwa für Simulink vorhanden sein.
Dagegen ist die Anzahl der zu unterstützenden Zielsprachen für den angestrebten Einsatz Embedded Target eher niedrig: C(++)
und vielleicht Java.
Aber die Vielfalt der Codegenerierung könnte steigen, eben wegen Multicore in C(++), Adaption an Laufzeitumgebungen für Optimierungen
und dergleichen. Es kann sein dass diese Vielfalt eben nicht aus der aufbereiteten Statement-Darstellung erwachsen soll, sondern
aus einer spezifischen Aufbereitung unter Kenntnis der Connections der Module. Das wäre topologisch.
Grafische Notationen in Modellen sind topologisch. Es könnte daher einfacher sein für diverse Grafische Modellierungstools,
die topologische Textrepräsentation zu erzeugen, anstelle sich jeweils um die Anweisungsreihenfolge zu kümmern.
11.1 Events in IEC61449, Abarbeitungsreihenfolge und Parallelität
Topic:.FBG_UML_norm.topoltxt.evparall.
Last changed: 2019-04-28
In Simulink (und Modelica) wird die Abarbeitungsreihenfolge vom Datenfluss bestimmt. Die Abarbeitungsreihenfolge der FBlocks
ist nicht direkt ersichtlich, die Simulink-Engine kümmert sich darum. Man kann keine Fehler machen bezüglich in der Reihenfolge
falsch zugegriffener Daten (ungewollte Totzeiten).
In IEC61449-FBD wird die Abarbeitungsreihenfolge von der Eventverdrahtung bestimmt. Sie ist damit im Modell vom Entwickler
vorgegeben. Wenn der Entwickler Fehler in der Zugriffsreihenfolge auf Daten hineinmodelliert, dann müssen diese per Fehleranalyse,
Debug, erkannt und korrigiert werden.
Welche Strategie günstiger ist, sei dahingestellt. Simple für den Anwender, braucht sich um nichts zu kümmern, oder simple
für das durchschauen was passiert. Jedenfalls ist die Analyse der Abarbeitungsreihenfolge im Simulink und die Umsetzung in
eine Eventverdrahtung angemessen. Verwendet man Simulink, ist es dann einfach für den Anwender, und die Umsetzung zeigt die
wirksame Abarbeitungsreihenfolge. Wird diese verändert, gelingt aber das Roundtrip in das Simulink-Modell diesbezüglich nicht,
da diese Information so nicht im Modell steht.
Bei der Eventverdrahtung zeigt sich eine Parallelität, die für die optimierte Codegenerierung für Multicore-Hardware ausgenutzt
werden kann. Dazu ein Muster-Simulink-Modell (nicht pragmatisch):
Das obige Bild zeigt ein kleines Simulink-Beispiel. Aus dem einfachen Datenfluss ist zu erkennen, dass das Innenmodul A1 jedenfalls
zuerst gerechnet werden muss. Danach kommt B. Wird der Ausgang 1 nicht benutzt, dann braucht B nicht gerechnet zu werden,
dass ist aber die Entscheidung nach der IEC61449-Textdarstellung hin zum generierten Code.
Das Innenmodul A2 kann parallel gestartet werden. Es muss aber vor B fertig sein. C liegt wiederum parallel zu B. Damit ist
dieses Modell grundsätzlich geeignet für 2 cores, wenn die Auslastung denn auch passt.
Die Eventverdrahtung nach IEC61449 müsste dann wie folgt generiert werden:
Der FBCL_A hat zwei Eventin- und outputs da er innen zwei unabhängige Dinge tut, die nur wegen der sachlichen Zusammengehörigkeit
in ein Submodul eingeordnet sind. Die zwei Events werden aber für die Anwendung parallel angestoßen (muss nicht sein, kann
auch komplexer sein).
Der E_REND ist in diesem Zusammenhang wahrscheinlich falsch, er soll hier verdeutlichen, dass beide Events vorliegen müssen damit es
weiter geht. Das ist jedenfalls mit einer Statemachine realisierbar.
Das ev1O des FBCL_A steuert beide Parallelzweige wiederum an. D.h. ist der 1. Teil des FBCL_A fertig gerechnet, dann kann parallel FBCL_C laufen, und falls ev2O vorliegt, auch FBCL_B.
Eine Codegenerierung aus der textuellen IEC61449-FBD-Darstellung kann nun die jeweiligen ALGORITHM und Event-Verbindungen aus dem Text auslesen und die zugehörigen Operations mit ihren Aufrufen generieren.
Dass die Daten rechtzeitig bereitstehen, ist auch formell kontrollierbar aufgrund der Event-Daten-Relations. Beim Entwurf
und Test des Modells auf IEC61449-Ebene muss man sich dies anschauen.
11.2 Events aus topologischer Verdrahtung
Topic:.FBG_UML_norm.topoltxt.evTopol.
Last changed: 2019-04-28
Das obige Bild zeigt ein Submodul in Simulink mit einigen Verküpfungen. Farblich sind Teile markiert, die unabhängig zu rechnen
sind:
a1() wird berechnet, sobald x1 und x2 besetzt sind (deren Events gekommen sind). Für die Optimierung zur Laufzeit wird es aber nur berechnet, wenn ya1 benutzt wird (das Outpin angeschlossen ist).
e() ist für a1() notwendig, wird berechnet wenn x1 und x2 anstehen und muss vor a1() berechnet sein.
a2() ist adäquat a1(). Es braucht nicht berechnet werden, wenn ya2 unbenutzt ist. Aber a2() kann parallel zu a1() berechnet werden.
b() wird berechnet, wenn x2, x2, x4 gekommen sind. Es kann parallel laufen. Die Ausgänge yb1 und yb2 sind zusammengefasst über den mux. Das ist eine Hilfskonstruktion, die bedeuten soll, dass yb1 und yb2 immer zusammen bereitgestellt werden, unabhängig ob einer der Ausgänge unbenutzt ist. Das ist hier nicht Ergebnis einer automatischen
Optimierung, sondern Ausdruckswille im Modell. Damit wird aber auch yb1 erst berechnet, wenn x3 und x4 anstehen, auch wenn sie hierfür nicht gebraucht werden!
c() wird berechnet sobald x2 gekommen ist. Es wird aber als Folge d) angestoßen.
d() wird berechnet nachdem c() berechnet wurde. Das ist eine update()-Routine für die Speichervariable q im Simulink mit dem Unit delay1/z ausgedrückt.
Hinweis: Das update() wird immer zuletzt gerechnet. Zu beachten ist, dass updates möglicherweise andere Speichervariable benötigen, deren update
also entweder erst danach gerechnet wird, oder die Speichervariablen werden dupliziert berechnet und im lezten Schritt gemeinsam
kopiert. Das ist wichtig, weil es sonst Fehlfunktionen wegen falscher Zuordnungen des zeitlichen Verlaufs von Werten gibt!
Die Unterteilung in diese Operationen ist aus Simulink-Codegeneriergründen sinnvoll, weil:
Wird nur ya1 abgegriffen, dann wird auch nur a1() berechnet. Adäquat für a2(), b() usw. Die aufwändige Operation für d() entfällt wenn c() nicht berechnet wird.
Wird yc abgegriffen, dann wird c() berechnet, und danach mit d() das update der Speichervariable ausgeführt.
Dies bewirkt die Simulink-Codegenerierung aufgrund Wegfalls nicht genutzter Signale.
Werden alternativ diese farbigen Operationen als eigenständige Operationen des FBlock realisiert, dann erfolgt etwa gleiches
Verhalten: Wird y1a benötigt, dann wird alles berechnet, was x1 und x2 versorgt, dann a(). Die Operationen c() und d() werden, wenn nicht benötigt, auch nicht aufgerufen.
Diese Betrachtung ist unabhängig von der Event-Verbindung nach IEC61449. Es sind zwei Dinge maßgeblich:
Weglassen von Operationen wenn diese nicht benötigt werden, wenn die Ausgänge nicht abgegriffen werden.
Paralleles Bearbeiten.
Die Abarbeitung innerhalb der farbigen Kästchen wird im Simulink durch den Signalfluss determiniert. So wird in a2() der Betrag zuerst berechnet, bevor in Diffya2 subtrahiert wird. Diese Abarbeitungsreihenfole ist aber dann komplex, wenn Submodule eingegliedert sind, die selbst wieder
unabhängige Operationen haben bzw. in der Simulink-Codegenerierung mittels flatten über Modulgrenzen aufgelöst sind - und andererseits konsistente Ausgänge haben sollen. Daher ist es angenehm, wenn für eine
spezialisierte Codegenerierung nicht aus dem Modell-Datenfluss gearbeitet werden muss (dazu sind möglicherweise Details der
Modell-Darstellung notwendig), sondern wenn die Abarbeitungsreihenfolge als Event-Queue nach IEC61449 aufbereitet ist.
Das zugehörige Bild in IEC61449 sieht dann wie folgt aus (TODO derzeit noch unvollständig, 2019-05-07):
Die fehlenden Datenverbindungen sollten nicht allzu stören, lokal gibt es kleine Typprobleme. Es sind die gleichen Verbindungen
wie im Simulinkbild. Neu hinzugekommen sind die Eventverbindungen.
Im Bild ist erkennbar, das selbst die Summierung für ya1 und ya2 parallel ausgeführt werden kann. Man muss bedenken, dies ist ein kleines Beispiel. Ist die Summierstelle ein umfangreicher
Ablauf, dann lohnt sich die parallele Abarbeitung in mehreren Cores. Dazu sind zweimal EvAnd vorhanden, die intern eine kleine Statemachine enthalten. Für die C-TargetCodegenerierung wird nicht die Statemachine realisiert
sondern aufgrund der AND - Beziehung der Events die Parallelität und Synchronisierung (Join) generiert.
Die Rückwärtsauflösung von den Ausgabeevents ist für die Codegenerierung relevant. Wenn Ausgang yc nicht benutzt wird, dann braucht es nicht das evd. Folglich braucht es keine Verarbeitung der T1-Funktionalität mit dem F_MOVE als Speicher-FBlock für q und der zuvor berechneten Summe aus (q + x2). Wenn nur evb verlangt wird, dann braucht es auch nicht das Eingangsevent ev1, damit entfällt die Funktionalität für die Bildung von x1. Man bekommt also die gleichen Einsparungen an Laufzeit wie in Simulink.
Die Eventverbindungen ergeben sich aus dem Datenfluss im Simulink. Sie werden hier explizit dargestellt und sind eine Hilfe
für die Codegenerierung. Der Datenfluss braucht für die Codegenerierung nicht mehr extra analysiert werden. Das ist mit der Simulink_to_FBCL Konvertierung
dann bereits erledigt.
11.3 Generierter Code nach IEC61449 aus Simulink
Topic:.FBG_UML_norm.topoltxt.smlkgen.
Last changed: 2019-05-07
Das obige Simulink-Modell wurde nun aus den gespeicherten Informationen aus dem slx-File (enthält XML) so aufbereitet, dass
eine textuelle Darstellung etwa nach IEC61449 generiert wurde. Bezüglich der Events sieht das Ergebnis wie folgt aus:
FUNCTION BLOCK ParallelSimple
EVENT_INPUT
ev_x1 WITH x1;
ev_x2 WITH x2;
ev_x3 WITH x3, x4;
END_EVENT
EVENT_OUTPUT
evo_ya1 WITH ya1;
evo_ya2 WITH ya2;
evo_yb1 WITH yb1, yb2;
evo_yc WITH yc;
evo_q;
evo_x1x2;
END_EVENT
VAR_INPUT
....
FBS
....
EVENT_CONNECTIONS
ev_x1 TO Mulx1x2.ev, Sumx1q.ev, Sumx1x2.ev;
Mulx1x2.evo_x1x2 TO Sumx1x2.ev, Diffx1x2.ev, evo_x1x2; (* x1x2 *)
Sumx1x2.evo_ya1 TO evo_ya1; (* ya1 *)
Diffx1x2.evo_ya2d TO Diffya2.ev, Abs.ev; (* ya2 *)
Diffya2.evo_ya2 TO evo_ya2; (* ya2 *)
Abs.evo_abs TO Diffya2.ev; (* ya2 *)
Sumx1q.evo_y TO Gain1.ev; (* q *)
Gain1.evo_gain1 TO SumT1q.ev; (* q *)
SumT1q.evo_y TO zq.ev; (* q *)
zq.evo_q TO Sumyc.ev, Sumx1q.ev, SumT1q.ev, evo_q; (* q *)
Sumyc.evo_yc TO evo_yc; (* yc *)
ev_x2 TO Diffx1x2.ev, GainX2.ev, Mulx1x2.ev, Sumyc.ev;
GainX2.evo_yb1 TO evo_yb1; (* yb1 *)
ev_x3 TO Sumx34.ev;
Sumx34.evo_yb2 TO evo_yb1; (* yb1 *)
END_CONNECTIONS
Das ist ein maschinelles Ergebnis nach heutigem Stand.
Nach der Eventverbindung in (* ... *) ist als Comment angegeben, auf welches Ausgangsevent sich insgesamt die Eventverbindung bezieht. Diese Info ist nicht für
die weitere Codegenerierung aus dieser Textdarstellung bestimmt sondern dient tatsächlich nur der Kommentierung.
Ein- und Ausgänge wurden auf ein Event zugeordnet, im Beispiel yb1 und yb2 wegen dem im Modell definiertem gemeinsamen Mux. x3 und x4 wurden deshalb automatisch zusammengefasst, weil beide gleich benutzt werden. Das ergibt sich also aufgrund der Logik. Die
willentliche Zusammenfassung im Modell mit einem Mux wäre auch hier möglich.
Das Abs im Block a2() wurde eigentlich im Beispielmodell eingebracht, damit die Sequentialisierung, zuerst, Abs dann die nachfolgende Differenz richtig generiert wird. Das derzeitige Generatorergebnis sieht aber so aus, dass:
Diffx1x2.evo_ya2d TO Diffya2.ev, Abs.ev; (* ya2 *)
das Abs als Folge von Diffx1x2 (Signal yad2 berechnet wird, das ist korrekt.
Aber auch Diffya2 schonmal angestoßen wird, obwohl diese noch
Abs.evo_abs TO Diffya2.ev; (* ya2 *)
benötigt. Die Sequentialisierung ist also in dieser Eventfolge nicht ausgedrückt. Statt dessen eine parallele Bearbeitung,
aber mit einem EvAnd, der notwendigen Bereitstellung von zwei Events Diffx1x2.evo_ya2d und Abs.evo_abs also Vorbedingung zu Diffya2.ev. Das EvAnd ist im Text noch nicht korrekt ausgedrückt, es benötigt einen eigenen FBlock.
Diese Nicht-Sequentialisierung ist letztlich für den Multicore-Gedanken (parallel execution) besser, denn die direkte Verbindung
Diffx1x2 zu Diffya2 könnte auch noch einige komplexere Elemente enthalten, so dass die parallele Abarbeitung zweckdienlich ist. Würde die Textdarstellung
auf diesem Niveau bereits sequentialisieren, dann würde diese Information nicht enthalten sein.
Die Sequentialisierung, die sowohl für eine Singlecore-Codegenerierung als auch für eine einfachere Darstellung in einer IEC61449-Grafik
und deren Realisierung in einem Laufzeitsystem zweckmäßig wäre, kann im Nachhinein auch noch aus der parallelen Darstellung
gewonnen werden:
Primär wird ein IEC61449-Text generiert, der Parallelführung von Events und deren EvAnd enthält.
Daraus, über reine Textkonvertierung, wird sequentialisiert, in dem das EvAnd auf eine Serienschaltung der Berarbeitung aufgelöst wird (ähnlich wie ein AND mit Logikgatter mit einer seriellen Verdrahtung
von Kontakten realisiert werden kann).
Man hat dann zwei Textrepräsentationen, mit und ohne sequentielle Auflösung. Aus dem Modell muss nur die primäre generiert
werden (parallel), was zunächst als einfacher angesehen werden kann. Die Serialisierung ist ein Algorithmus unabhängig von
dem verwendeten Tool der Grafischen Modell-Darstellung.
Die Arbeiten dazu sind im Fluss.
12 Literaturangaben nicht als Internet-Link
Topic:.FBG_UML_norm.lit.
Die Normen selbst sind nicht als Internetlink auffindbar sondern Dokumente, die bestellt und bezahlt werden müssen. Daher
wird an dieser Stelle die jeweilige Quelle benannt.
/IEC61131-3/: INTERNATIONAL STANDARD IEC 61131-3 Second edition 2003-01, Reference number IEC 61131-3:2003(E)


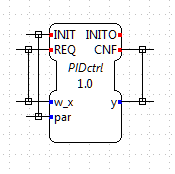 Bild: 4Diag. In der 4diac-Darstellung des
Bild: 4Diag. In der 4diac-Darstellung des