for several application (same core functionality).
between departments of the same company and as standard all over the world.
for some years or more than ten years.
Do not confuse reusing with legacy code. Reusing is using sources which are known for several applications. Legacy code is old code, which is running well but it might be unknown in details or in sum. Legacy code is only able to use with black
box, wrapper, and 'do not touch an running system'. Legacy code is a bad choice for a good software.
One time tested, one time reasoned, one time in an version archive, always correct and able to use.
Kerningham and Richie have worked
in a world in 1970 with expensive computers.
with regard to behavior of machine code and assembly language
with careful programming
with less ressources on the computer.
With the C-language, they have created a standard which was good enough from 1970 till 1989. But from 1990 until now, the
C-language and the derived C++ language became the first language for most of target systems (and for PC programming too).
For all processors a C and C++ compiler is available.
The standards and thinking from the 1970 and 1980 have some leakage for safety programming. The C99 standard (see for example
http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf) has repaired some things, but it was comming too late, and it was hesistantly implemented 10 or more years after that. Usually
a standard should be the result of all existing best practice or quasi standards. But in the 1990 and after that there were
too much different approaches:
C for Unix, BSD, POSIX
C and C++ from Microsoft, relieving the C from Borland for PC usage under MS-Windows: Another company, an own approach.
C for some embedded processors, which standard, rather conservative or not, or looking for POSIX, or better for Microsoft?
And no strong and widely accepted organisation which take care of the standard.
1 The problem with String processing in C
Topic:.portab_emC.strncpy.
The C of 1970 from K&R has the 'big idea', Strings should be simple char[]-arrays. A pointer char* is a String already. The String is ending with a 0. Simple & Easy.
In other languages Strings are characterized with a pointer to the character array and an extra value, the size. That is better
if a substring (part of a string) is referred. It is better too if the length is needed. But the decision for 0-terminated
strings in C is omnipresent, with some less problems.
1.1 The history of snprintf
Topic:.portab_emC.strncpy..
The sprintf is simple from the eyes of K&R:
char buffer[128]; //much enough
sprintf(buffer, "That is the message, number =%d\n", value);
The value of a int has at most 10 digits, the buffer is great enough, it runs. You must count the number of characters manually. You should
work carefully. You should debug all code. That were the rules for programmers in the past century.
But what about
sprintf(buffer, "a String: %s", stringpointer);
If the stringpointer has a problem with its length respectively the end-0 was overridden by a bug or a a malicious attacker,
it may be a problem outside the tested area of software. Then the next bug occurs: All memory after buffer will be destroyed.
Therefore sprintf should be rejected by the programmers community already in the 1990-th. The C99 standard defines snprintf:
char buffer[128]; //much enough
snprintf(buffer, sizeof(buffer), "a String: %s", stringpointer);
That may be ok (it has another problem, the strlen-Problem, see below, But it does not override the buffer). But: The IDE
Visual Studio 6 from 1998 does not know snprintf. This IDE was often used in the 2000th. The first Visual Studio version which has impemented snprintf was VS 2015, about
16 years after the standard were defined.
What to do if snprintf was used in sources, but it is not available in a target's library. It is not trivial to deliver an replacement (other than
for strnlen, see below). A simple solution is:
In this solution the LEN argument is ignored. It is assumed that the software was tested on PC. If the https://en.wikipedia.org/wiki/Variadic_macro are not available on a target compiler, a snprintf function can be written with variable arguments to ignore Len:
In the emC sources a emc/source/emC/formatter_emC.c was written some years ago because the problem was known. It offers an own solution for printf-adequate requests.
1.2 The strlen and strchr problem
Topic:.portab_emC.strncpy..
The strlen overrun problem does not seem to be present in some forums. But follow the example from praxis:
static char myString = "example"; //it has 8 character with ending 0
myString[7] = 'x'; //a bug or indirect from a malicious attacker
int len=strlen(myString);
The strlen function does not find the '\0'. It continues to search. The chance to find a 0-byte in the near following memory is about 0..99%. It is 0% if the memory
is not 0-initialized, and not used furthermore. Then the memory may contain such content as AA AA AA AA depending on the hardware RAM circuits. Consequently the strlen runs till the end of memory. On end of memory either the access force a crash (faulty memory access), or it reads non-existing
or repeating memory. It runs furthermore and needs calculation time. The system does not respond. An interrupt routine which
invokes strlen for a simple action overruns in time.
Other systems have recognized this problem, too and offer a solution. There is a strnlen(str, maxsize) on Linux (http://man7.org/linux/man-pages/man3/strnlen.3.html) or a strnlen_s(str, maxsize) in the C11 standard. Why doesn't the C11 standard use the existing function name strnlen from the existing quasi-standard?
The emC library defines an own algorithm which can use as replacement for a non existing strnlen:
strnlen_emC(char const* string, int maxlen);
defined in emc/source/emC/string_emC.h. The compl_adaption.h defines:
#define strnlen strnlen_emC //only if the existing compiler suite does not define it.
The strnlen should be able to use any time. The idea for maxlen is:
If the length, derived from the expected maximal length, is limited, use this limit. In an error case it is not important
which length the string really has:
char buffer[128]; //limited
int zString = strnlen(anyString, 127); //no more cannot be used.
if(zString == 127) { ... }//maybe set a warning hint in a log system
strncpy(buffer, anyString, zString);
buffer[zString] = 0;
In this example, the maxlen argument of strlen_emC additionally saves the time checking the zString before using it. It is <=127 in any case.
If the expected length is unknown, but a range can be estimated, use that value to prevent long time searching end of string:
int zString = strnlen(anyString, 1500);
if(zString = 1500) { //the end is not found...
Because the memory is accessed readonly, data cannot be disturbed. The probability to catch the end of the memory area can
be excluded with a proper memory layout.
The strnlen can be used in any situation. Don't use strlen.
char* strnchr_emC ( char const* text, int cc, int maxNrofChars)
defined in emc/source/emC/string_emC.h. The compl_adaption.h defines:
#define strnchr strnchr_emC //only if the existing compiler suite does not define it.
1.3 Is strncpy unsave?
Topic:.portab_emC.strncpy..
Microsoft's Visual Studio (2015) warns on using of strncpy:
error C4996: 'strncpy': This function or variable may be unsafe. Consider using strncpy_s instead.
The uncertainty of strncpy is a user's problem. Only if the description of the operation is not regarded in details, the program is unsafe. The problem
is: If the maximal length is reached, no 0 is appended. A subsequent fault can occur if the following algorithm needs the '\0'. A simple workarroung is:
char buffer[100]; //limited
strncpy(buffer, anyString, sizeof(buffer) -1); //only 99
buffer[sizeof(buffer)-1] = 0; //write in any case a last 0
But: Which programmer spends the effort on any usage of strncpy?
One point of interest: The strncpy was defined in C99, but the Visual Studio 6 from 1998 knows it. It is one of the conventions of some C-Compiler which are
a quasi-standard before C99.
The intension of strncpy is: copy a limited number of characters, but only till 0, and fills the rest with 0. The difference to memcpy is: memcpy
copies in the same way, copies the end-0, but does not fill the rest with 0, instead copy the content after 0 furthermore.
The result is similar, but memcpy reads in memory after the String end-0 and writes in memory maybe information which should
not written.
Both strncpy and strlcpy fill the rest of the destination with 0. It uses some calculation time. In effect the destination buffer should be provided
with an initial 0 content, or it should be cleaned on end of an algorithm with some more copy actions. The offered strncpy_s is standard in C11. It seems to be overengineered. That simple str... routines should be used without system overhead and effort. It's sole purpose is to copy characters. No more sophisticated
things.
The emC library offers a simple alternative: (in emc/source/emC/string_emC.h):
/**Copies the src to the limited dst with preventing overflow and guaranteed 0-termination.
* or copy a given number of characters without 0-termination.
*
* @param dst A buffer to hold either a 0-terminated C-string with at least sizeDst free bytes inclusive end-0
* or a destination for a non-0-terminated String.
* @param src C-String maybe 0-terminiated
* @param sizeOrNegLength if positive then number of use-able bytes from dst inclusive terminating \0.
* if negative, then the maximal or given number of chars to copy maybe without end-0
* @return The number of characters copied without ending \0 .
* The user can check: if(returnedvalue >= sizeDst){ //set flag it is truncated ...
* The return value is anytime a value between 0 and <=sizeDst, never <0 and never > sizeDst.
* The return value is the strlen(dst) if it is < sizeDst.
*/
extern_C int strcpy_emC(char* dst, char const* src, int sizeOrNegLength);
and
/**Copies a defined Number of characters to a buffer. It is adequate strncpy(src, dst, length)
* but it fills only one \0 if src is shorter than length.
* It does not write a terminating \0 if src length >= the given length argument.
*/
inline int strncpy_emC ( char* dst, char const* src, int length){ return strcpy_emC(dst, src, -length); }
The last one operation is adequate to strncpy but does not waste calculation time with filling the buffer with unused 0. (Only one '0' is necessary). You can replace all strncpy with strncpy_emC in your application.
The strcpy_emC(...) operation, it is real simple, achieves both requests, the 0-termination and the capability of strncpy. It is slightly compatible
with strncpy (a replacement), only the sizeorNegLength should be given as negative value. It is complied with the 0-termination idea if
Strings are copied to a limited buffer, with positive size value.
The routine is able to use for two approaches:
Copy with limited dst, goal of strncpy, strlcpy and strncpy_s
Copy of a determined number of characters without '\0'-termination, goal of strncpy
If a char[]-array should be filled, the 0-termination is not important (because the length of the array is known) but on a
shorter src-String reading after the String should prevented, use:
char buffer[20];
int nrofValidChars = strcpy_emC(buffer, mySrcString, -(int)sizeof(buffer));
if(nrofValidChars >= sizeof(buffer) { ... it matches exactly or it is truncated.
It is the same result like strncpy (with positive number of chars). buffer[] is not 0-terminated if the String is longer.
But if the String in buffer should be 0-terminated, use:
char buffer[20];
int nrofValidChars = strcpy_emC(buffer, mySrcString, sizeof(buffer));
if(nrofValidChars >= sizeof(buffer){ ... it was truncated.
Example with combination with strnchr_emC:
char buffer[128];
char const* exampleInput = "identifier=23.5";
int posSeparator = strnchr(exampleInput, '=', sizeof(buffer));
strcpy_emC(buffer, exampleInput, posSeparator); //only the identifier
In this simple example the maximal value of posSeparator is limited to the buffer size by using strnchr. Therefore no overflow
can happen on strcpy_emC.
The next example shows an effective implementation of a concatenation for simple string algorithm.
The zcpy reaches 0, if the buffer limit is reached. zdst is incremented for concatenation.
Important note: All the str... routines are thought for simple basicly string operation maybe with known String settings usual in an embedded target system.
For example prepare log messages or error outputs on a (simple) display.
For complex String operations for example parsing files you should use more powerful libraries. Elsewhere the user algorithm
is full of detail operations. You should think on handling leading and trailing spaces (example above if the input contain
" identifier = 23.5 "), error checks etc. etc.
For complex String operations you should use either preparation of texts in another process or task using Java (it is more
safe in programming) if you have for example a linux kernel on your embedded target. Or you should use some known C++ libraries,
or the emc/source/J1c/String*.c capabilities. These sources run in a standard C and come from Java sources (translated to C). The same algorithms are available
in Java language as well as in C.
2 Problem of conflicting definitions of fixed sized integer types
Topic:.complAdapt.int32.
In the far past C does not define integer types with a defined bit width. The thinking and approach in the former time was:
The register width of the processor is important. That is the int type.
Algorithm written for the highly developed and expensive 32 bit machines may not be used properly for 16-bit machines.
What about 24-bit-machines. For that int has the register width of 24 bit.
It is better to have a short integer for less memory consumption (for arrays) and a long integer which is 32 bit for 16-bit.machines.
That was adequate to the situation of non-microprocessor-computers of the 1960- and 1970-years. Because C was used for microprocessors
with 16 and 32 bit register width with flexible registers, the decision that was made for C is no more adequate. As a work
arround all users have defined their own fixed size int types with slightly different notations in very different header files.
For the own application it is a perfect world, without thinking outside the box.
But if sources are reused, build applications from different sources, compatibity problems have to be managed, usually with
hand written specific adapted solutions.
The C99 standard has defined these types (int32_t etc) 10 years after its became necessary, and this standard was not considered 10 or 20 years after its definition. This
is the situation. The last one is not a problem of disrespect, it is a problem of compatibility.
Lets show an example:
Simulink defines int32_T via typedef and uses it in its generated sources. This is the case with version 2016a (and further).
The user wants to use int32_t according to C99 in its environment.
This results in a pointer type error on a C++ compiler or a warning. The types are indentically for the users eye. The int32_T is written with typedef in the generated simulink header rtwtypes.h. and the int32_t is defined via typedef in the stdint.h header in the C99 environment. Both are independent and not compatible.
What should be done?
An unchecked cast of all usages on user level is not recommended!
Using the simulink types in the environment application is the recommended option of the Mathworks company. But this means
that all sources, re-used, from another team or supplier should be subordinated under the Simulink style. Subordinate under
C99 may be ok, but subordinate under all regulations of all parts of a software is not possible.
The possible and convenient decision is:
All parts of software uses that notation which is given. Do not change it. It may be the simulink convention, the C99 one
or an own one.
The compl_adaption.h should define all known and used integer fixed size types. In this situation (application uses simlink) the definded types
should base on the Simulink types with #include <rtwtypes.h> from the Simulink generated code. That is necessary because the code generated secondary sources from Simulink should not
be changed.
The C99 types should be defined based on the Simulink types too:
#define int32_t int32_T
Therefore all fixed size types are compatible.
The including of the stdint.h which defines the C99 types should be prevented. This is possible with defining the guard of that header. Including the stdint.h results in compiler errors because the same type are defined twice.
All other user specific files which defines adequate types should be prevented from including too, for the same reason.
The definitions of all the fixed point types should be done via #define, not via typedef. Therefore it is possible to do #undef, this may be necessary in some source situations.
For the user's sources it means:
#include <compl_adaption.h> immediately as the first include or better #include <applstdef_emC.h> in any source. It may be indirectly done already via other emC headers.
Do not include stdint.h in the users sources. The C99 types are already defined via the compl_adaption.h.
Do not include the other definitions of fixed sized int types, trash it in favor of the compl_adaption.h. The simplest form is: #include <compl_adaption.h> or better include <applstdef_emC.h in the header instead the own definitions.
The majority of the user's sources which uses the specific fixed size int types can stay unchanged, no extra work to do!
3 Basic decisions for portable programming
Topic:.portab_emC.decid.
The most important decision is: Do write sources portable and reuseable without adapting the source lines. It is possible.
You have to want it.
To reach that target: Never use special offers of a special system! Use only things which are supported at least from a Unix/Linux
and from a Microsoft Compiler. Then check whether it is a C-Standard. First check C99. C11 might be overengineered and may
be more for PC programming, in my mind.
Use simple algorithms. Usual they do what you want.
If the behavior of an used standard function may not to be compatible: Use your own. It can be a more simple impementation
sufficient for your and adequate requests.
Don't think: Microsoft, Google, Linux, Apple & co are your Grand Lord which says what you have to do. Think for yorself.
Do not use standard libraries from any system which are not guaranteed standard. Don't include windef.h or similar one in your application. Use your own header.
The C standard consists of the compiler behavior itself and also of the standard libraries and headers:
The Libraries are add-ons to the compiler suite. You can use standard libraries or not. You can exclude standard libraries
by compiler (linker) switches.
The compiler behavior itself is important for compatibility. But with special defines the compatibility can be reached:
The C99 does define the inline keyword known from C++ for C too. The first Microsoft compiler which knows it is VS 2015. But you can
#define inline static
for an compiler in the emc/.../compl_adaption.h which does not know the inline keyword. The behavior is good enough:
The static keyword prevent linker errors for double existing labels, because it is local for the compilation unit.
static routines are tried to be expanded inline if the compiler can optimize this. Some compilers which do not regard C99 do so.
Therefore static for C-functions in header is adequate to inline.
It means you can adapt the compiler behavior to your sources.
_
Don't adapt your sources to a standard or compiler, write a wrapper instead:
If you realize that your target compiler does not support a routine (for example snprintf), don't change your source. Write a very simple wrapper. For this example:
The size argument is ignored, but the functionality should be tested and does not cause buffer overflow.
3.1 What library functions and keywords to use
Topic:.portab_emC.decid..
If a standard library function
1) is knwon in established systems such as Unix derivates,
2) it is able to adapt to systems which does not know it
3) it is not expected that this identifier is used in another system with another meaning or argument order
4) the signature (arguments) are coherent,
you should use that function in your sources and adapt it to a system which does not know it. The topic 3) is the unknown
one. The problem is: If any new compiler defines that function in a system header which is usual included (such as stdio.h) then it may be incompatible with a necessary own wrapper.
Example to use:
strnchr, strnlen: Because this routines are able to adapt, they are well defined in a BSD environment and are known from some users.
Example not to use:
strncpy in a possible adapted form should only be used if the behavior is the same like the standard: Don't guaranteed 0-termination.
The better routinen strcpy_emC(...) should not mapped to a known routine because in this time no routine is known which has the same functionality.
Example to use:
strcpy_emC is well defined, the sources are existing as open source, you can use it with that special names.
Naming rules, prefix, suffix:
The known problem is: name clashes. Using exoting suffixes (prefix possible, not recommended) prevents name clashes.
#inlude <pkg/path/file.h>
It is a feature of C from begin, but selten used. It is recommended. The header files should be arranged in well defined directories.
Then the directory should be specified too. Therewith confusion is prevented with header files from systems or applications
with the same name. It is adequate to the package path which is usual for Java package path: Therewith a non-specified but
all complied rule is: start with your internet address in package path. In that way the package path is unique world wide.
3.2 Using operation system access
Topic:.portab_emC.decid..
If you have a special operation system, such as Embedded Linux or QNX, you could think, writing all of your sources regarding
to your OS. You have an emulation on PC, it is all okay. But if you have core algoriths, which only need a simple process
synchronisation (a semaphore), and this core algorithm may proper to reuse in another platform, with another or without an
OS, it fails.
The sources which deals expensive with the multi threading system or do io-operations, are less. Most of sources need only
standard access to the OS-level. The most of operation systems works similar. Often a common intersection of some OS access
methods can be used.
Therefore the decision should be: Using an Operation System Adaption Layer (OSAL). The adaption to your target OS can be thin walled, maybe only a simple parameter adaption in an inline routine.
The another decision should be: Use simple access methods.
A semaphore with all its specialities is not a candidate to use. For mutual exclusion access to a data area use a mutex object:
os_lockMutex(thiz->mutex);
... //consistently data access
os_unlockMutex(thiz->mutex);
You need a mutex object, it is to create. Usual only the handle have to be stored. To adapt this simple approach to a multithreading
system which does only knows simple semaphore, it is a special handling with the semaphore (set and release). If this source
is used in a simple interrupt / backloop system (for a cheap processor), the mutex is the disable interrupt - as global mutes. It runs just as well. The example TestMutex in the emctest.zip download shows how does it run under Windows, and under a simple 16 bit TI430 processor.
3.3 Reusing and definition of specificas, versioning
Topic:.portab_emC.decid..
The emC approach - embedded, mulitplatform, reusing, C - assumes that the same unchanged sources should be used for test on
PC and run on the target hardware. But how does it works?
The image shows in yellow the unchanged application sources. There have modifications internally, but this modifications are
not in the sources, they are in the compiled code. The modifications are determined by the content of the applstdef_emC.h headerfile. This file controls some macros, some compiler switch settings and some more included files. The applstdef_emC.h is included in all files, inclusively the OSAL sources. Therefore the compiler regards that definitions. Without changing
sources the running result have the necessary modifications.
The OSAL, the other approach, is target/system-specific. In the image above this block is in the same pale blue color, but
it is the os-specific adaption as well as the os itself is shown in the same green color.
Of course, some sources are specialized to the target system. That sources organzize the threads, the interrupts on the cheap CPU target etc. That sources should be written and tested target-specific. But they may not be application-specific, my be unchanged
for several applications or variants on the same target.
The reuseable Appl-sources are the same on all that targets, one time tested usual on PC, running of several targets in several applications (for sub
functionality).
Of course, that sources are versioned. Another application can contain really changed reused sources. But the noteworthiness
is, that this sources can be reused for the other application for a new version again.
The reuseable sources are used for application A. The application B was built, but with an new version. Of course, for bugfixing
a side branch should be used for application A. Only the necessary things should be changed. But for a new version of application
A, all operation experience with that functionality is used from application B too, with using the newest version of the sources.
The bugfix of appl-A may a bugfix for the main branch of the sources and it is merged, and revised. Therefore the new version
of appl-A contains the fix too, maybe in a better form. This experience on appl-A is used on the new version of appl-B later
too.
Last but not least, the reuseable source may come from graphical (model-oriented) programming. That is an important fact for
transparency of functinality. It is better than line code.
Some of tools for graphical model-oriented or model-driven programming have the approach to generate code immediately proper
for the specific target system. In this case the test of functionality is only possible on model level - and in the target
environment as end-usage test. The test on model level is necessary, very usefull and important, of course. But a test with
the generated sources in independent different environments and the storing and versioning of the generated sources are important
too. Both, the graphical and the generated line sources should be stored and versioned. It is a more complex process as it
will be seen from the graphical tool provider.
4 What is emC
Topic:.portab_emC.emC.
emC means embedded multiplatform C. It is the challenge to programm platform-independent portable - in meaning of the name.
But emC is really a pool of sources - for portable embedded development in C.
The first sources are from about 2004, with some experience in C and C++ in the years before with platform independency. The
first name of that source pool was CRuntimeJavalike because the style of C-Programming with ObjectOrientation was injected with the style of programming in Java. Java is not
favored in spheres of the embedded and C programmer. But that is inequitable: Java was developed in the years 1990 till 95
primary for the different processors of embedded platforms, for a unique sources. In that time C was not widespread, usual
programming was done in assembler or some special languages. For this goal some useful definitions are part of Java, for example
unique thread handling, proper file handling etc. If the Java development was finished, on the one hand C was established
for embedded already, and on the other hand the Internet with several platforms was born and a comming hype. Java was used
as platform to execute code in the browser firstly, not for embedded platforms. Later, Java was improved, it was one of the
first platform which executes the necessary atomic access for fast threadsafe execution etc. The Garbage collector, typically for Java, prevents an exact fast realtime behavior in standard Java. But a special garbage collector, in conclusion
with balanced usage of dynamic memory in longliving fast realtime embedded applications enables the usage of Java for such
targets. There are some Java Virtual Machines which executes Java bytecode on different target systems, for example from https://www.aicas.com (Jamaica VM). Last but not least to Java: It is not slowly. The machine code of Java is the byte code, contained in class
files stored in a zipped file. It works with a dynamik linked library approach. Loading a functionality (a module) loads the
jar file (which is a zipfile) if it is not preloaded already. Then it unpacks the content, searches the required class file
and translated it with a so named just in time compiler (JIT-Compiler) to machine code of the target processor. The machine code is executed exactly so fast as C-compiled machine code. The differences
are the optimizing routines from a C-compiler and the JIT-compiler, but that optimizing routines are supposed the same. There
is no reason whether a JIT compiler is better of worse than a C compiler. But one difference is: Java machine code is more
secure. A programmers failure in the C source may cause data disturbing, maybe crashing. In Java some safety mechanism prevents
crashes in any case, they need a little more computation time. If the same safety mechanism are programmed in C, they need
the same time. The enforcment to effectivity is done by many applications of Java for server programming of course. For embedded
applications, especially for the Jamaica VM from aicas, the Java bytecode is pre-compiles on installation time (for small footprint processors) or on startup time, so that the
start of execution of a special function is fast. That is the truth of Java.
What does the expert's side glance to Java means for C programming:
Java has a unique concept. Of course there are the packages java.io and java.nio (new input output) etc. But that is able to expect over 20 years. The compatbility is a cherished property. Some routines are identificated
as 'deprecated' since some years, but they run well nevertheless.
The multithreading routines are simple and unique.
It is ObjectOriented per definition.
The first super class java.lang.Object has basicly functionality able to use in any environment.
The reflection mechanism is obvious and simple. It is adapted to C usage for symbolic access to all data.
Nevertheless the base routines in the emC source pool are not depending on Java concepts. They are firstly proper for C embedded usage.

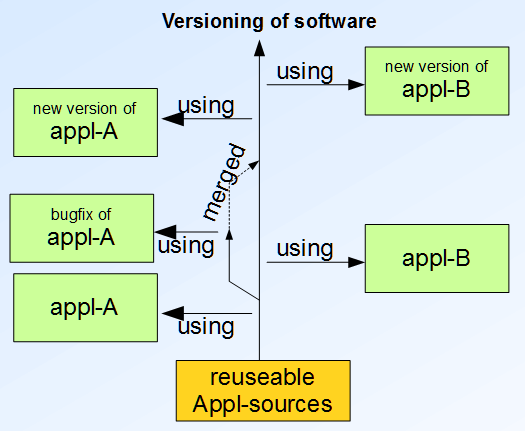 Bild: Versioning of reused sources
Bild: Versioning of reused sources
 Bild: Sources from graphical programming
Bild: Sources from graphical programming