Inhalt
Topic=.CHeader.HeaderDocu.
Headerfiles in C oder C++ enthalten meist Information für Schnittstellen in maschinennaher Notation:
Genauer Byteaufbau von Daten beispielsweise in Telegrammen als struct{....}
Prototypen für Funktionsaufrufe in C. Die Funktionen selbst sind irgendwo geeignet implementiert und werden vom Linker zugewiesen. Das ist ein statisches Interfacekonzept.
class-Definitionen für C++. Insbesondere rein abstrakte Klassen sind in C++ identisch mit den Interfaces in Java.
Definition von Konstanten als enum oder #define
Aus reiner softwaretechnischer oder implementierungsspezifischer Sicht ist ein Headerfile als solches ausreichend als Dokumentation, wenn er halbwegs kommentiert ist. Aus dokumentatischer Sicht ist das nicht akzeptabel. System wie Doxygen, dem Javadoc adäquat produzieren HTML-Seiten, die besser lesbar und navigierbar sind als der reine Quellcode. Aber dennoch erwartet man von einer ordentlichen Softwaredokumentation eine aufbereitete Information, die eine Schnittstelle verbaler erläutert als Quellcode oder Doxygen-Generate, und doch in Byteaufbau-Bildern oder Tabellen auf Details eingeht. Folglich wird man Hand anlegen und eine Dokumentation mit Word &co erstellen, die den Ansprüchen genügt.
Das muss jedoch nicht sein. Eine genügend ansprechende Dokumentation kann man auch rein generisch erzeugen. Wesentlicher Bestandteil sollen dabei die Informationen aus den Headerfiles sein. Dazu müssen die Headerfiles ordentlich dokumentiert sein, was ihren Wert selbst steigert. Diese Dokumentation sollte aber eingebettet sein in weitere Bestandteile, die das Umfeld erläutern. Dazu können Topics benutzt werden.
Topic=.CHeader.HeaderDocu..
Es muss eine bestimmte Form der Kommentierung in Headerfiles beachtet werden, die sich an die Javadoc-Richtlinien anlehnt, aber weiteres umfasst.
Die Informationen aus den Headerfiles müssen in XML vorliegen. Dazu kann ein ZBNF-Parser benutzt werden. Ein verwendbares ZBNF-Script ist Sbnf2Xml/Cheader.sbnf. (INSET:: Dieses Script liefert eine XML-Form ab, die beispielsweise auch zur Erzeugung von java-Programmen verwendet wird, die Datenstrukturen aus Headerfiles als byte[] verarbeiten (Cheader2Java).
Das damit erzeugte XML-Format wird zusätzlich nach dem standardisierten XMI-Format konvertiert:XSL-Script:_HeaderXml2Xmi.xsl. Die Konvertierung von Header-XML nach XMI ist unter anderem auch für eine UML-Darstellung des Inhaltes von Headerfiles nützlich. Der Vorteil ist hier, dass einige gleiche Dokumentationsgenerierung und -darstellung verwendet werden können wie für UML-Modellelemente.
Die XSL-Scripts für die Darstellung von UML-Dokumentation aus XMI befinden sich in XSL-Script:_UmlDocu.xslp. Bestimmte Informationen aus Headerfiles wie defines, die nicht UML-like dargestellt werden können, werden über das XSL-Script:_HeaderDocu.xslp gesteuert. Dieses Script liest die Informationen aus dem XML-Format des ZBNF-geparsten Files. Beide XSL-Script werden eingezogen als import bei der Dokumentengenerierung, im Übersichtsbild als special.xsl ausgewiesen.
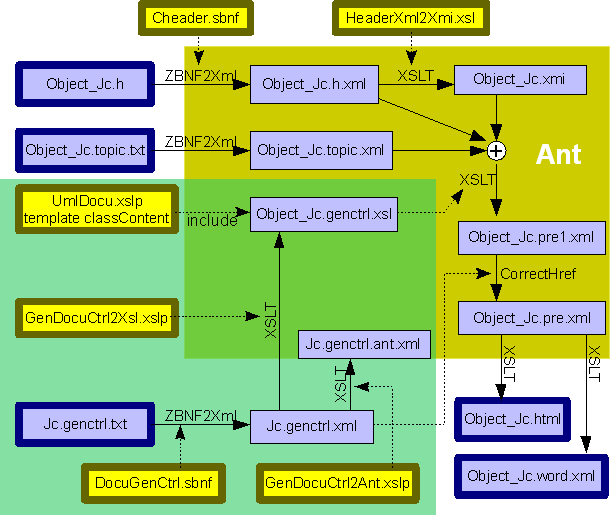
Topic=.CHeader.ImageHeaderDocu.
Im Bild ist am Beispiel der Generierung des Dokumentenfiles Object_Jc.html und des zugehörigen word.xml-Files gezeigt, welche Schritte in der Dokumentengenerierung aus Headerfiles durchlaufen werden. Das Beispiel ist aus dem Inhalt der Seite vishia: OOP in C, CRuntimeJavalike mit den aktuellen Files dargestellt.
Blau stark umrandet sind Quell-Files der Anwenderdokumentation, in diesem Beispiel der Headerfile selbst und ein Topics-File mit weiteren Erläuterungen ExampleJc:_Object_Jc.topic.txt, die in der Dokumentation erscheinen sollen. Ebenfalls blau umrandet ist der Steuerfile der Dokumentengenerierung des Anwenders ExampleJc:_Jc.genctrl.txt. Das sind die Quellen der konkreten Dokumentation. In diesem Steuerfile wird bestimmt, welche Informationen in welcher Reihenfolge erscheinen sollen, einschließlich Kapitelgliederung. In diesem File wird bestimmt, welche Informationen aus den Inputfiles ausgewählten und dargestellt werden.
Gelb stark umrandet sind Quell-Files der Generierung (Steuerscripts). Diese steuern das Aussehen der einzelnen Teile. Der Anwender kann diese Files anpassen, das ist aber nicht Sache des End-Anwenders, der die Inhalte konkreter Dokumente bestimmt, sondern der Anwender-Aufbereitung der Dokumentengenerierung. Diese wird in vielen Fällen konstengünstiger durch Inanspruchnahme von Dienstleistungen eines Softwarehauses erledigt werden können. Ein Blick in die Quellen zeigt die Komplexität. Die Hyperlinks aus dem Bild führen zu HTML-Abbildern der Files, damit sie in jedem Browser betrachtet werden können. Die Quellen sind im download:_XmlDocu_xsl zu finden.
Innerhalb der grünen Fläche sind alle Files zusammengefasst, die das Aussehen der Dokumentation bestimmen. Die Inhalte dieser Files sind konstant, wenn sich die Art der Inhaltsbestimmung der Dokumentation nicht ändert. Außerhalb der grünen Fläche befinden sich die Files, die die tatsächlichen Inhalte enthalten.
Die braune Fläche stellt dar, welche Generierschritte mit Eclipse-Ant ausgeführt werden. Der ant.xml-File zur Steuerung der Generierung wird selbst generiert. In diesem Bild nicht dargestellt ist ein Generierschritt, der die Quell-Files der Generierung (Steuerscripts) aus *.xslp nach *.xsl konvertiert.
Topic=.CHeader.CHeaderDocuSample_ObjectJc.
Die Generierung beginnt links unten außerhalb ANT mit der Konvertierung des Steuerfiles der Generierung (Dokumenteninhaltsbestimmung) nach XML. Das erledigt ein ZBNF-Parser. Das Steuerscript dazu ist Sbnf2Xml/DocuGenCtrl.sbnf, dieses Script bestimmt die Syntax des *.genctrl.text-Files. Die dort festgelegte Semantik wird für die Erzeugung des XML-Abbildes ExampleJc:_Jc.genctrl.xml genutzt. Das SBNF-Script wäre zu erweitern, wenn andere Arten von Inputfiles oder Input-XML-Strukturen für Dokumente benötigt werden. Das erzeugte XML-File wird später auch noch für die Korrektur der Hyperlinks benutzt.
Aus dem XML-File wird das ANT-Steuerfile, im Beipspiel ExampleJc:_Jc.genctrl.ant.xml erzeugt. Das Steuerscript für dessen Erzeugung ist XmlDocu_xsl/GenDocuCtrl2Ant.xslp. Es muss entsprechenden Erweiterungen des Sbnf2Xml/DocuGenCtrl.sbnf folgen und konkrete Anweisungen aufbereiten für weitere Dokumentenquellen, spezielle Verzeichnisse usw. Diese ersten zwei Schritte der Generierung sind in einem batch-File XmlDocu_batch/prepareAntxml.bat(Windows) enthalten.
Nachdem das ANT.xml-File generiert worden ist, wird ANT aufgerufen. Das ist im XmlDocu_batch/prepareAntxml.bat mit enthalten. Alle weiteren Schritte werden dann von Eclipse-ANT gesteuert. Damit wird die Reihenfolge der Generierung aus den Abhängigkeiten selbst festgelegt.
Weil im ExampleJc:_Jc.genctrl.txt steht, dass das Dokument Object_Jc aus den
input: Object_Jc.topic.txt input: Object_Jc.h
besteht und weil es für diese Inputs die Aufbereitungsvorschrift
prepXml: Object_Jc.topic.txt ->TextTopic2Xml ->Object_Jc.topic.xml; prepXml: ../CRuntimeJavalike/Object_Jc.h ->Header2Xmi ->Object_Jc.xmi;
gibt, wird im ANT die oben gezeigte Konvertierung nach ExampleJc:_Object_Jc.topic.xml und ExampleJc:_Object_Jc.xmi ausgeführt. Diese beiden Files werden dann mit dem ExampleJc:_Object_Jc.genctrl.xsl als Steuerfile mit dem vishia-XSLT-Translator konvertiert. Das XSL-Scripts ist ebenfalls aus dem Quellfile ExampleJc:_Jc.genctrl.txt generiert. Dazu werden die Anweisungen im Block (Beispiel)
Document "vishia - Object_Jc - Basis aller Daten" ident=Object_Jc
{
input: Object_Jc.topic.txt;
input: Object_Jc.h;
chapter "Object_Jc: Basis aller Daten"
{
topic(Object_Jc/*); //enthält ggf. mehrere chapter
}
chapter "struct Object_Jc - in Object_Jc.h"
{
p "Nachfolgende Dokumentation ist direkt aus den Headerfile-Kommentierungen
in Object_Jc.h generiert, daher in englisch:"
umlClass(**/Object_Jc, attributes=bytes);
}
}
benutzt. Hier steht, welche Inhalte benutzt werden und in welche Kapitel sie einfließen.
Das Ergebnis dieses Schrittes ist ein XhtmlPre-Format mit noch nicht korrigierten Hyperlinks. Die Hyperlink-Korrektur hat das Ziel, auf der Ebene des konkreten Dokumentes Hyperlinks aus den Quellen anzupassen. Die entsprechenden Informationen sind ebenfalls im Generier-Steuerfile ExampleJc:_Jc.genctrl.txt im Abschnitt HyperlinkAssociation angegeben. Aus diesen Informationen wird dann das HTML-Dokument erzeugt.
Style-Angaben sind sowohl im ExampleJc:_Jc.genctrl.txt, als auch in den Dokumentenquellen und auch in den Generierscripts möglich. Jede dieser Style-Quellen hat ihre Berechtigung:
In Headerfiles selbst wird es keine Styleangaben geben sollen.
In den Topic-Files sind bestimmte wenige Styleangaben möglich.
In den Generierscripts der Einzelinhalte aus Headerfiles sind Styleangaben wesentlich, hier wird bestimmt, wie die Dokumentation auszusehen hat.
Im Dokumentengeneriersteuerfile soll nur korrigierend eingegriffen werden.
Bei der Generierung wird noch ein File XmlDocu_xsl/HtmlFormatStd.xml in das HTML-File hineinkopiert oder in Link zu einem CSS_File wird generiert. Damit wird das letzliche Aussehen bestimmt.
Topic=.CHeader.TextStructureHeader.
.
Topic=.CHeader.TextStructureHeader..
Das Headerfile wird mit dem Sbnf2Xml/Cheader.sbnf geparst. Die dort enthaltene Syntax bestimmt die mögliche Syntax des Headerfiles neben den syntaktischen Erfordernissen der Compilierung. Die SBNF-Konvetierung verarbeitet aber auch Kommentare zu allen Einträgen und Strukturierungs-Kommentierungen. Vom C(++)-Comiler werden Kommentare einfach ignoriert.
Es gibt ein grundsätzliches Problem, was in der Praxis kaum ein Problem darstellt: Ein C(++)-Compiler führt vor der Syntaxprüfung einen Präprozessorlauf aus. Dabei wird eine einfache Text-Ersetzung von defines vorgenommen. Man kann nun in #define-Anweisungen sonst was reinschreiben, der Compiler sieht dann etwas ganz anderes als im originalem Quelltext steht. Der SBNF-Parser geht jedoch ohne diesen Präprozessor vom Quelltext aus. Eigentlich könnte auch hier ein Präprozessorlauf stattfinden, um Gleichheit der Verarbeitung zu erreichen. Aber in Standard-Präprozessor entfernt auch die Kommentare, und diese sind essentiell für die Dokumentation. Man bräuchte also dann einen Spezial-Präprozessor. - In der Praxis werden meist defines in einer verträglichen Art verwendet. Damit lassen diese sich in die SBNF-Syntax einbauen.
Ein anderes Problem, die Tatsache dass ein Headerfile oft von #include anderer Headerfiles syntaktisch lebt, ist ebenfalls kaum ein Praxisproblem. Der SBNF-Parser interessiert sich nicht für die Auflösung von Identifier, die halt in vorigen Headerfiles deklariert werden. Lediglich bei unmöglichen Tricks wie einer öffnenden Klammer in einem includierten File, die schließende Klammer steht dann im geparsten File, wird die SBNF-Syntax etwas Probleme haben. Wenn man so will - Header, die nach Regeln einer guten Softwarequellgestaltung geschrieben sind, sind für den SBNF-Parser kein Problem.
Das vorliegende SBNF-Script Sbnf2Xml/Cheader.sbnf kann gegebenenfalls nicht alles, was laut C- und C++-Standards erlaubt ist und auch ggf. benötigt wird. Es ist allerdings an einigen Headers aus der Praxis erprobt. Was beispielsweise fehlt, ist die Verwendung des extern "C"-Konstruktes. Dafür ist aber ein define METHOD_C vorgesehen. Das vorliegende SBNF-Script ist erweiterungsfähig und wurde auch schon einigemale wegen praktischer Erfordernisse erweitert.
Topic=.CHeader.TextStructureHeader..
Ein Headerfile enthält oft sehr viele Deklarationen und Definitionen. Für eine bestimmte Dokumentation soll dabei ausgewählt werden. Daher ist es angebracht, den Quelltext im Headerfile in Bereiche zu unterteilen, die jeweils eine geschlossene Einheit darstellen. Eine struct-Definition ist eine geschlossene Einheit.
Aus der Anwendungspraxis insbesondere im Thema vishia: Java & C ist die Orientierung auf Strukturen mit zugehörigen Methoden als Klassen gelegt. Dazu ist eine Einteilung verwendet, die im Sbnf2Xml/Cheader.sbnf berücksichtigt wird: Jeder Bereich beginnt dabei mit
/*@BEREICHTYPE name @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@*/
Als BEREICHTYPE gibt es verschiedene Festlegungen:
|
Bezeichnung |
Bedeutung |
|
PACKAGE name |
Eine Package-Bereichsüberschrift soll nur am Anfang stehen. Sie ist für die UML-konforme Darstellung gedacht. |
|
CLASS_C name |
Das ist ein Bereich, der eine gleichnamige |
|
CLASS_C_VIRTUAL |
Das ist der Teil einer C-like Klasse, der die Definition virtueller Methoden enthält. |
|
ARRAY name |
In diesem Teil einer C-like-Klasse werden Array-Strukturen definiert. Die Konzepte dazu ist in vishia: Java & C zu finden. |
|
TOPIC name |
Es ist möglich, in Headerfiles als Kommentar auch textuelle Topics zu notieren. |
|
DEFINE_C [name] |
Ein Block ausschließlich mit |
|
CLASS_CPP |
C++-Klassen. |
Damit erfolgt die Grobunterteilung des Headerfiles. Macht man dies nicht, dann kann man auch auf Infos in XML nach dem Parsen zugreifen. Der XmlDocu_xsl/HeaderXml2UmlXml.xsl ist aber darauf abgestimmt, da sonst keine UML-like-Darstellung erfolgen kann.
Topic=.CHeader.TextStructureHeader..
Die Art der Kommentierung, so wie sie im Sbnf2Xml/Cheader.sbnf verlangt ist, ist an Javadoc angeleht. Dabei stehen Kommentare immer über den betreffenden Elementen in der Form
/**Beschreibung * weitere Zeile */ int Definition;
Oft ist es üblich, Kommentare
int Definiton; //dahinter zu schreiben.
Das ist platzsparender, aber in Javadoc nicht üblich. Das Sbnf2Xml/Cheader.sbnf lässt sich erweitern, dass es beides kann. In Doxygen ist die Art der Kommentierung mit Paramtern sehr weit einstellbar. Es ist aber eher ein Segen, das Javadoc mit seinen klaren und festen Regeln für eine bessere Einheitlichkeit gesorgt hat. In diesem Sinn sollte man die zweite Variante //Kommentare dahinter nur als auch möglich für die Fälle, wo es kurz sein soll, anbieten. Selbstverständlich ließe sich das SBNF-Script auf alle Varianten, die syntaktisch fassbar sind, anpassen. Das muss dann auch sein, wenn in einem Projekt bestimmte Kommentierungsvarianten vorgeschrieben und üblich sind.
Topic=.CHeader.ShowStruct.
Strukturen sind zunächst die wichtigsten Einheiten für eine Dokumentation, da mit ihnen Datenschnittstellen beschrieben werden.
Eine Grafik ist oft übersichtlicher und kann schnell wiedergefunden werden, als endlose Listen. Auch in handerzeugten Doku wird oft eine Byteaufbau-Grafik von Datenelementen in Strukturen gezeichnet.
Wenn im Steuerfile der Dokumentengenerierung wie ExampleJc:_Jc.genctrl.txt in einem Kapitel geschrieben wird:
umlClass(**/Object_Jc, attributes=bytes);
dann erscheint nach der Konvertierung im XSL-File ExampleJc:_Object_Jc.genctrl.xsl an der entsprechenden Stelle
<xsl:for-each select="/root/XMI/Model//Class[@name='Object_Jc']">
<xsl:call-template name="umlClassContent" ><xsl:with-param name="attributes" select="'bytes'"
/></xsl:call-template>
</xsl:for-each>
Damit wird also im UML-like-Abbild des Headerfiles ExampleJc:_Object_Jc.h.uml.xml die entsprechende Klasse selektiert, damit das xsl-Template umlClassContent gerufen, aber mit der Information, dass Attribute als Bytes dargestellt werden. Im genannten Template im XSL-Script:_UmlDocu.xslp wird daraufhin nach dem XSL-Template umlClassBytes verzweigt. In diesem Template wird mit rekursiven Aufruf und Zählen der Byteanzahl pro skalaren Typ (int, float, int16 usw.) eine Strichgrafik aus +--'--+ erzeugt, die den Byteaufbau darstellen. Inwieweit man an dieser Stelle besser SVG oder anderes erzeugen könnte, sei Zukunftsvision. Jedenfalls ist die einfache Strichgrafik besser als Listen und für alle Medien darstellbar.
Unter der Strichgrafik werden dann die Attribute entweder in Adressreihenfolge mit Angabe der relativen Position oder in alphabetischer Reihenfolge dargestellt.
Topic=.CHeader.StructUmlClass.
Der Gedanke, Strukturen und zugehörige Funktionen als UML-Klassen aufzufassen, ist von einer C-geprägten Programmierung bestimmt, die sich aber auch in C++-Umgebungen einsetzen lässt. Dazu einige wertende Worte zu C und C++:
C ist ein besserer Makroassembler. Das ist nicht abwertend gemeint sondern unterstreicht die Nähe der C-Programmierung zum Ablauf im Maschinencode. C-Programmierer wissen sehr oft genau, was die CPU treibt. Sie müssen es ggf. auch wissen, wenn im embedded Bereich mit kleineren (langsameren) Prozessoren und knappen Speicherressourcen gearbeitet wird. C hilft dabei, nicht in die Assemblerprogrammierung zurückfallen zu müssen.
C++ ist wesentlich mächtiger und erledigt einige Dinge der Hochsprachenprogrammierung nützlicherweise automatisch. Deshalb ist aber die Nähe zum Maschinencode schon nicht mehr gegeben. Wer weiß schon genau, was ein Compiler macht, wenn er einen Konstruktor aufruft einer mehrfach erbenden Klasse aufruft oder wenn eine throw-Anweisung kommt.
Es gibt daher Gründe, in C zu programmieren. Ein anderer Grund ist der, dass das Speicherlayout einer C++-class nicht unbedingt compilerunabhängig feststeht. Bei C kann man aber erreichen, das eine struct compilerunabhängig definiert ist. Das ist wesentlich für einen Datenaustausch über Prozessorgrenzen. Dennoch sollte man nicht und muss man nicht die Objektorientierte Denkweise an den Nagel hängen, wenn man C programmiert. Auch in Assembler kann man grundsätzlich OO programmieren, man muss es nur selbst machen.
Eine Struktur, der C-Funktionen zur Bearbeitung zugeordnet werden, und auf deren Daten also nicht direkt zugegriffen wird, ist als OO-class auffassbar. Das Prinzip ist in vishia: Java & C erläutert. Im Sinne der Dokumentengenerierung mit diesem Gedankengut kann man unter Nutzung der Bereichsklammer
/*@CLASS_C name @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@*/
die Strukturen und Funktionen (dann Methoden genannt) zusammenführen und als eine Klasse dokumentieren. Da der Zwischenschritt XSL-Script:_HeaderXml2UmlXml.xsl eingefügt ist (er lässt sich auch weglassen), kann man die selben Scripts in XSL-Script:_UmlDocu.xslp benutzen wie bei einer Dokumentengenerierung aus einem UML-Modell.
Topic=.UmlDocu.umlClass.
Klassen aus einem UML-Modell können in eine Gesamtdokumentation in verschiedener Hinsicht eingefügt werden:
Gegebenenfalls möchte man nur einen Überblick bekommen und will daher lediglich beschreiben, wozu die Klasse da ist, was sie grob gesehen tut. Das kann der Fall sein in einleitenden Kapiteln.
Die Anwendung der Klasse kann von Interesse sein, nicht aber ihr innerer Aufbau. Das ist insbesondere bei Schnittstellenklassen der Fall, aber auch aus Sicht von außen auf eine Implementierungsklasse. Dabei sollen dann nur public-Elemente dargestellt werden, ggf aber auch protected-Elemente, wenn diese Klasse als Basisklasse vorgesehen ist.
Möglicherweise möchte man nur einen Überblick über gegebenenfalls zahlreiche Methoden einer Klasse darstellen.
Eine vollständige Dokumentation einer Klasse wird alle Methoden, Attribute und Assoziationen umfassen, mit ihrer kompletten Beschreibung. Die Implementierung von Methoden soll aber in der Regel nirgends in ein Dokument einfließen, das wird überlicherweise auf Programmquelltextebene (ggf. mit einem UML-Tool) betrachtet.
Denkbar ist aber durchaus, dass die Implementierung einzelner Methoden dargestellt werden soll.
Entsprechend diesen unterschiedlichen Anforderungen ist es notwendig, die Dokumentengenerierung steuern zu können. Das erfolgt im textuellen Steuerfile der Dokumentengenerierung.
TODO: ein Beispiel, am Beispiel genaues darstellen.
TODO
ERROR: not found ---/root//topics:topic[@ident='XmlDocuGen']/topics:topic[@ident='StateofCompletion']/topics:topic[@ident='todoXsl']---
TODO